
[Docling] 코딩 인터뷰 실전 적용: LLM을 위한 Union-Find와 Spatial Indexing
Performance · 코딩 인터뷰 단골 문제가 AI를 위한 문서 파싱의 O(n²) 병목을 해결하는 방법

LeetCode에서 유니온-파인드 문제(Number of Islands, Accounts Merge 등)를 풀어봤다면 아마 이런 생각이 들었을 것이다. 이걸 실제로 언제 쓰지?
여기 실제 사용 사례가 있다. AI가 사용할 수백만 개의 PDF를 처리하는 문서 AI 툴킷 Docling은 ML 레이아웃 모델이 반환하는 중첩된 바운딩 박스를 정리하는 데 유니온-파인드를 사용한다. 이 과정이 없으면 문단이 중복되거나 표가 조각나는 문제가 발생한다.
ML 모델은 왜 중첩된 박스를 반환할까
ML 레이아웃 모델(YOLO, DETR, LayoutLM 등)은 문서를 이해하는 것이 아니라 “여기에 표가 있을 확률 91%.”처럼 확률을 예측한다.
docling-project/docling:layout_model.py#L198-L210
모델은 TEXT, TABLE, PICTURE, CODE, SECTION_HEADER와 같은 다양한 문서 요소를 감지한다.
이 모델들은 완벽하지 않다.
중복 예측: 같은 요소가 약간씩 어긋난 박스로 여러 번 나타난다.
표 파편화: 큰 표가 여러 영역으로 분리된다.
예측 충돌: 문단 감지 영역이 표 감지 영역과 겹친다.
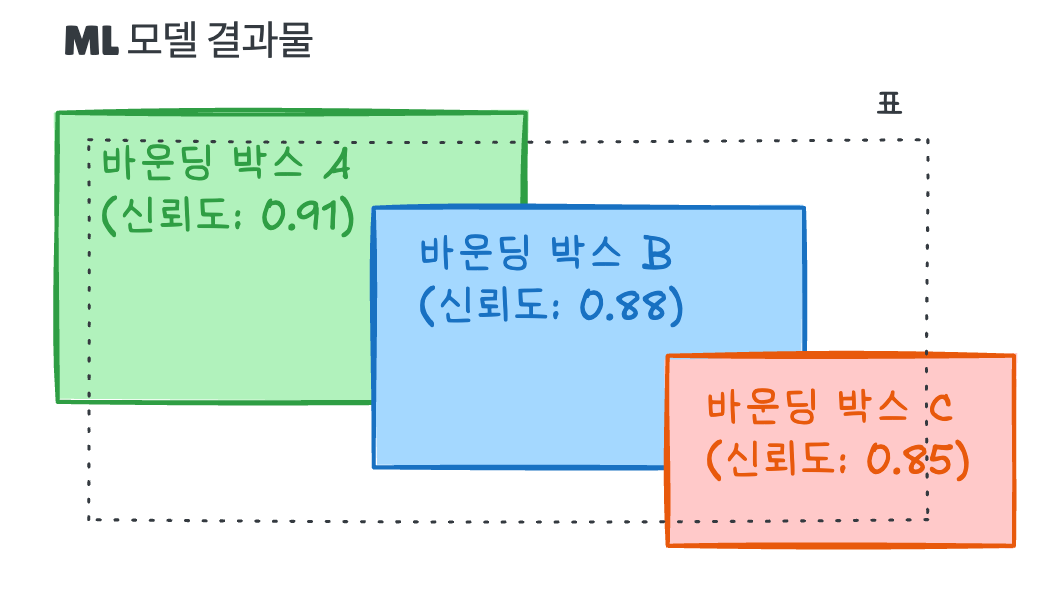
박스 A가 B와 겹치고, B가 C와 겹치지만, A는 C와 겹치지 않는다. 박스 세 개 모두 같은 표를 감지한 것이다. 이들을 어떻게 병합할까?
문제: 전이적 중첩
중첩은 전이적이다: A가 B와 겹치고, B가 C와 겹치면, 박스 세 개 모두 같은 그룹에 속하므로 병합해야 한다. 이 정리 과정이 없으면 문단이 중복되거나 콘텐츠가 조각나는 문제가 생긴다.
모든 쌍을 비교하는 단순한 접근 방식은 O(n²)이다. 유니온-파인드는 연결 요소를 추적함으로써 이 문제를 우아하게 해결한다.
유니온-파인드 구현
Docling은 scipy나 networkx 같은 의존성을 피하기 위해 최소한의 유니온-파인드 클래스를 직접 구현했다.
docling-project/docling:layout_postprocessor.py#L16-L46
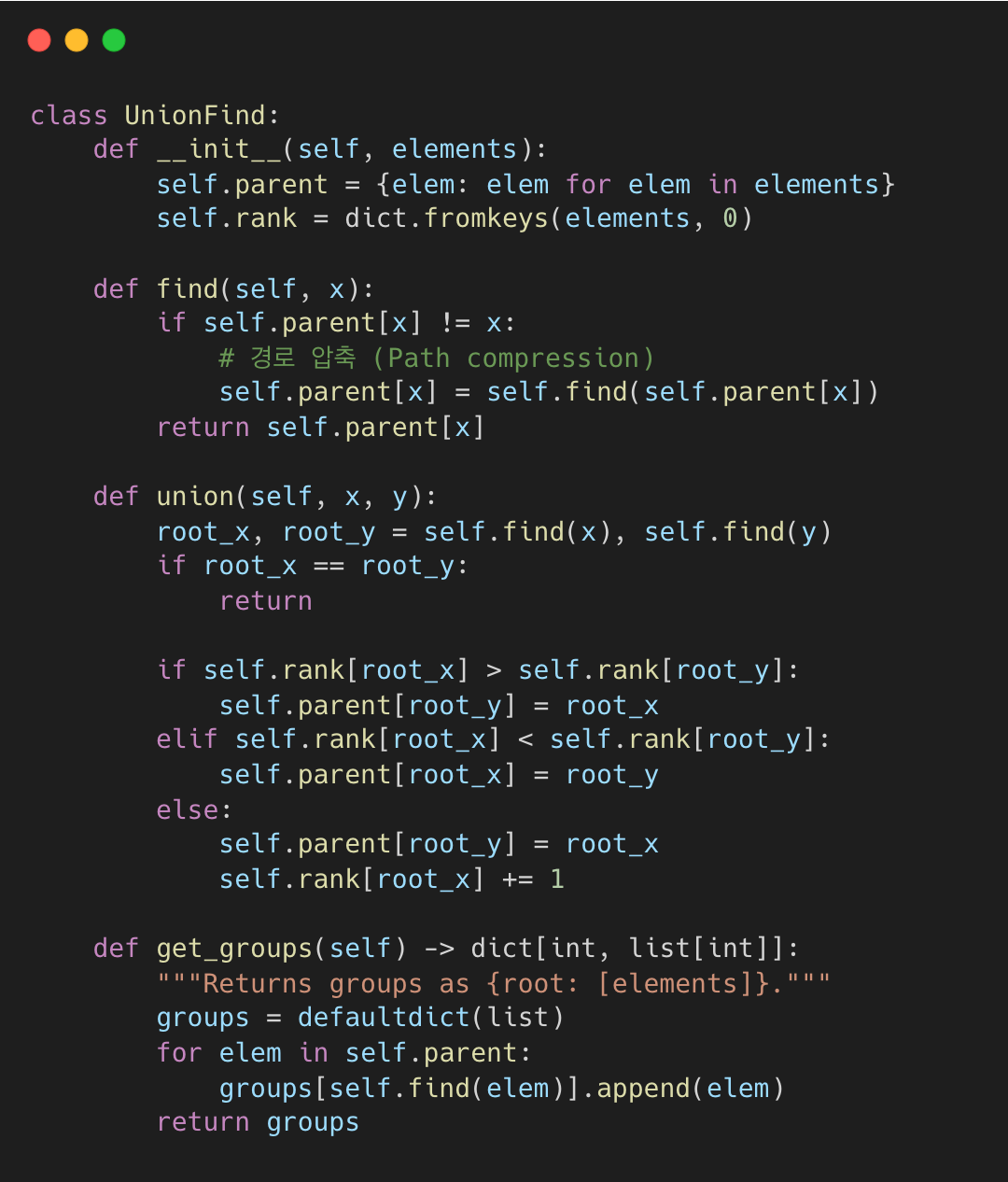
이 구현은 O(1)에 가까운 시간 복잡도를 달성하기 위한 두 가지 최적화 방법을 사용한다.
1. 경로 압축(Path Compression): find() 호출 시 트리 구조를 평탄화한다.
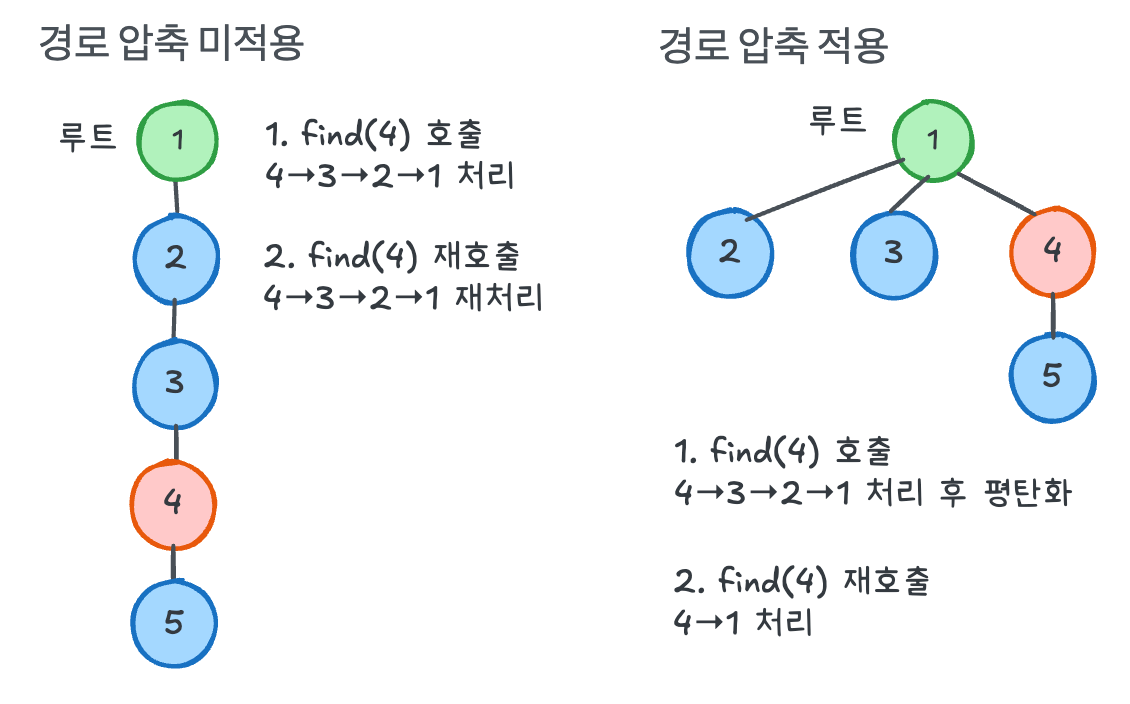
find()를 호출하면, 경로에 있는 모든 노드가 루트를 직접 가리키게 된다. 이후 이 노드들에 대한 조회는 O(1)이 된다.
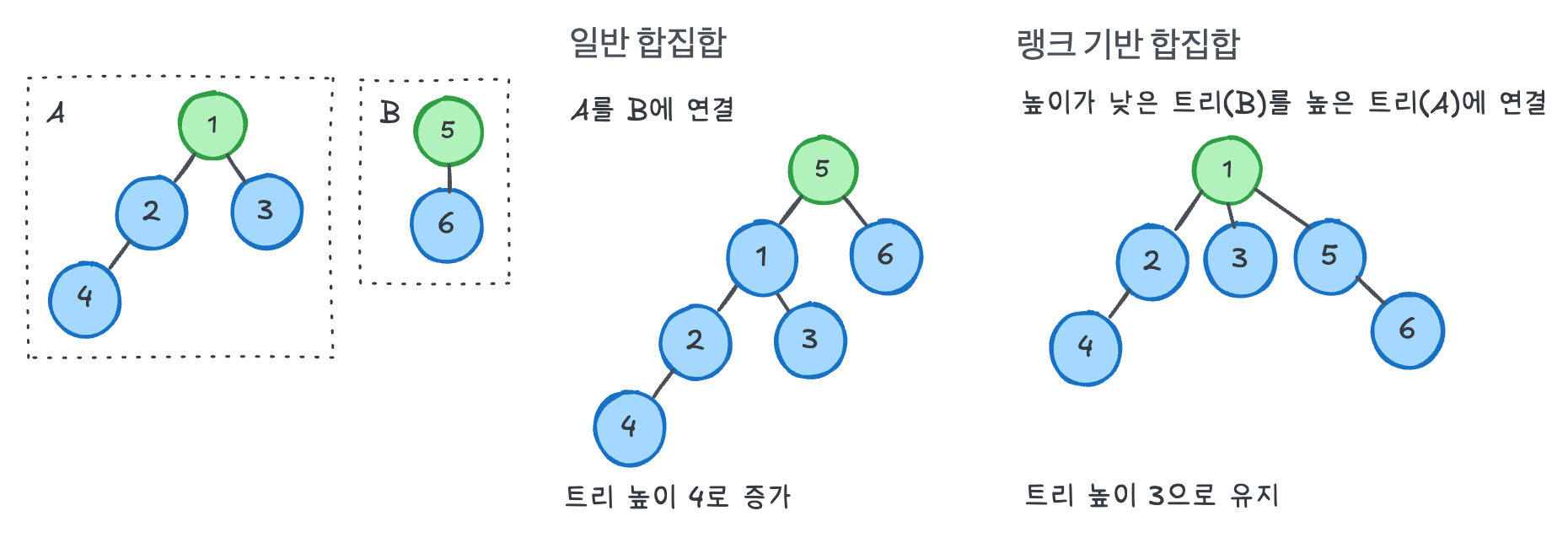
2. 랭크 기반 합집합(Union by Rank): 깊이를 최소화하기 위해 짧은 트리를 긴 트리 아래에 붙인다.
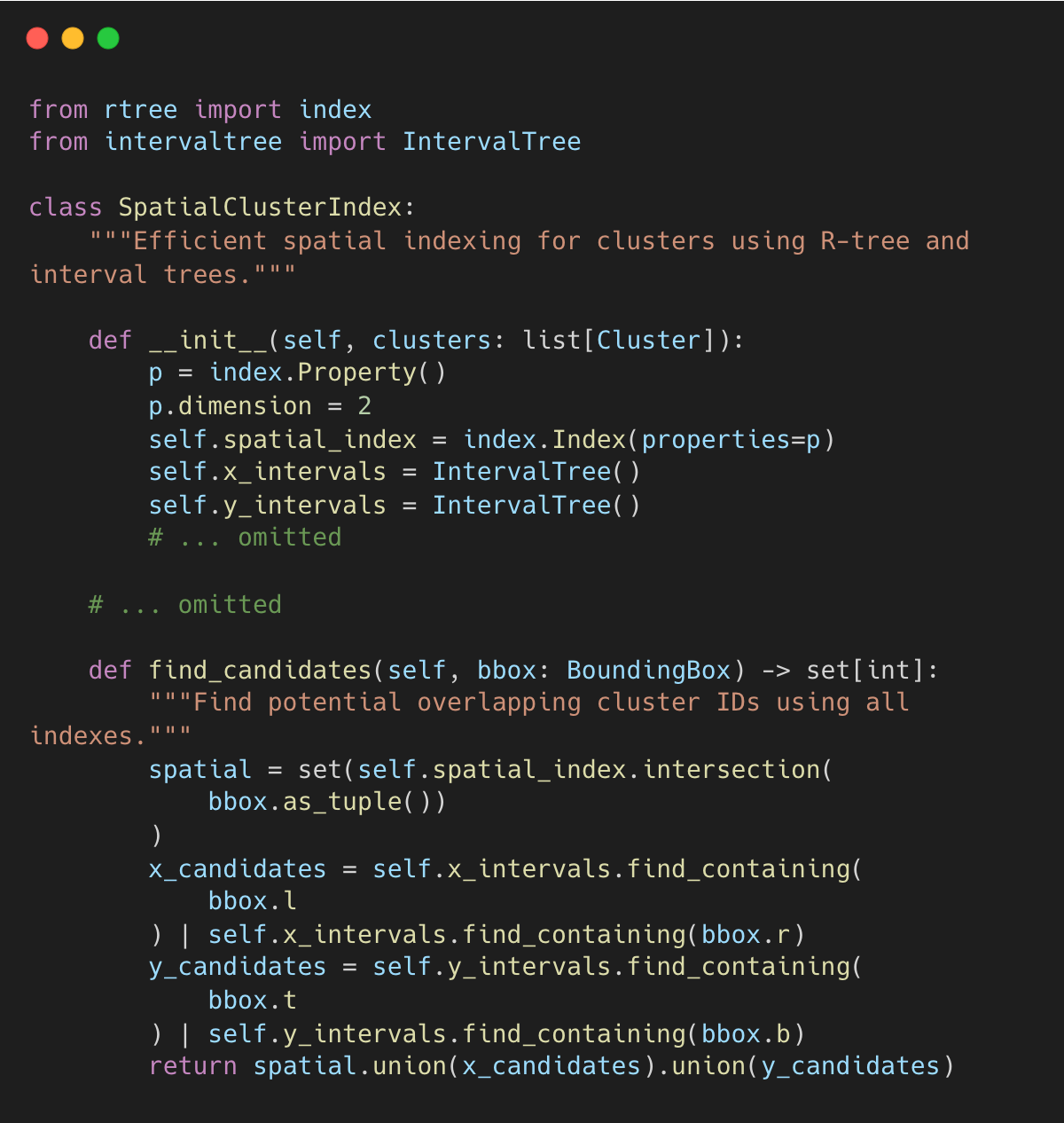
효율적으로 중첩 후보 찾기
유니온-파인드로 박스들을 그룹화할 수 있지만, 먼저 어떤 박스들이 중첩되는지 식별해야 한다. 모든 쌍을 하나씩 비교하면 시간이 오래 걸린다.
Docling은 공간 인덱스를 사용하여 O(log n) 시간에 인접 객체를 조회한다:
1. R-트리: 2D 사각형을 위한 전통적인 공간 인덱스이다.
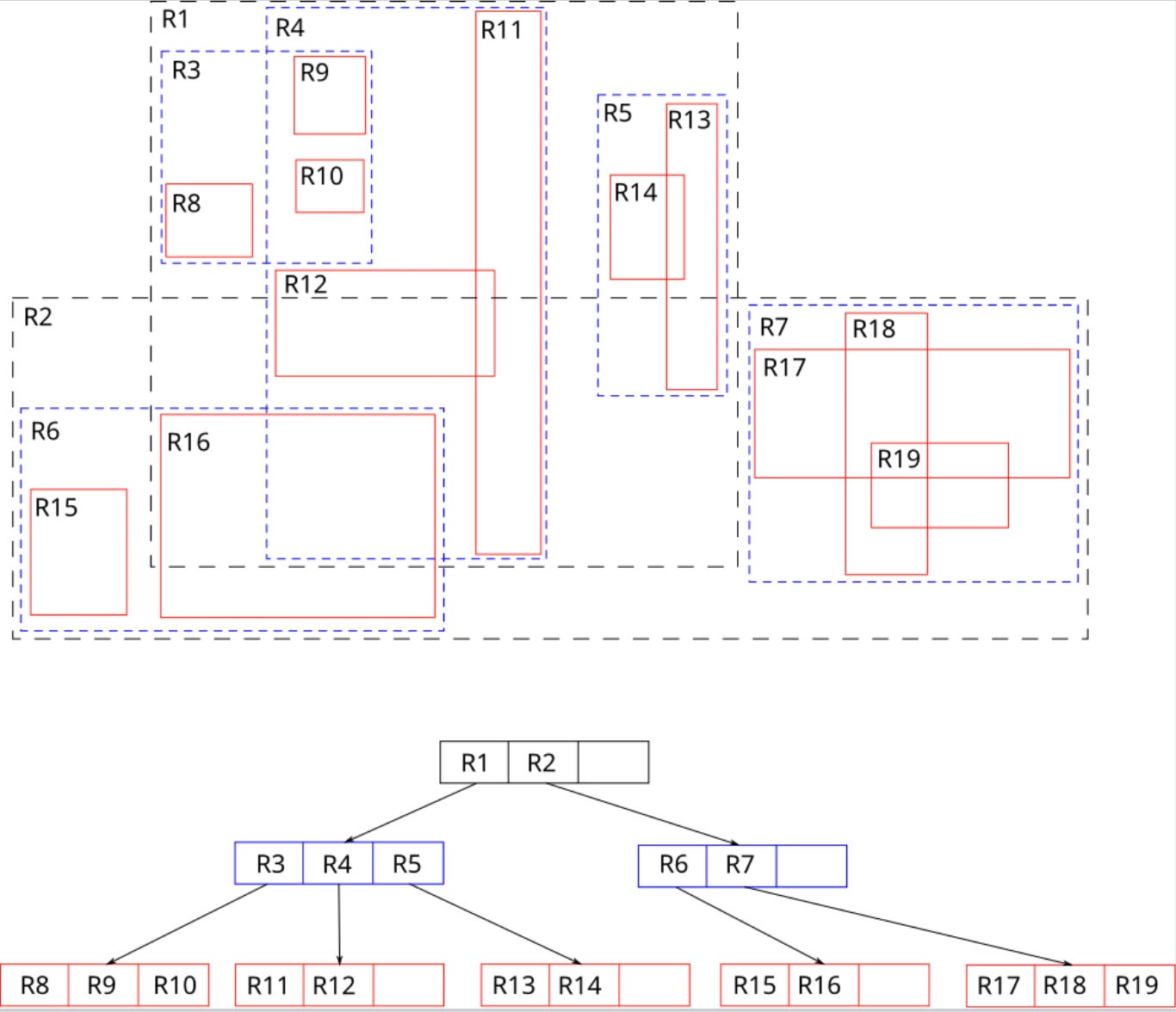
위 이미지(출처: 위키피디아)에서 R18과 겹치는 것을 찾으려면 R7만 탐색하면 된다.
{kind=link}
2. 간격 트리(Interval Trees): X좌표와 Y좌표를 위한 1D 인덱스(LeetCode의 Merge Intervals 문제와 유사)이다.
삼중 인덱스 전략
Docling은 신뢰성을 높이기 위해 R-트리와 간격 트리를 결합한다.
docling-project/docling:layout_postprocessor.py#L49-L83
문서 파싱 과정
원본 바운딩 박스에서 중복 제거된 클러스터를 추출하는 방법은 다음과 같다.
공간 인덱스 구축: 모든 클러스터(ML 모델이 반환한 바운딩 박스)를 R-트리와 간격 트리에 삽입한다.
중첩 찾기 및 합집합: 인덱스에서 후보를 조회한다. 중첩이 임계값을 초과하면
union(A, B)를 수행한다.그룹 추출:
get_groups()를 호출하여 연결된 클러스터 집합(예:{A, B, C})을 반환한다.최선 선택: 각 그룹에서 하나의 클러스터(가장 높은 신뢰도)를 유지하고, 나머지 클러스터의 콘텐츠를 흡수한다.
docling-project/docling:layout_postprocessor.py#L487-L542
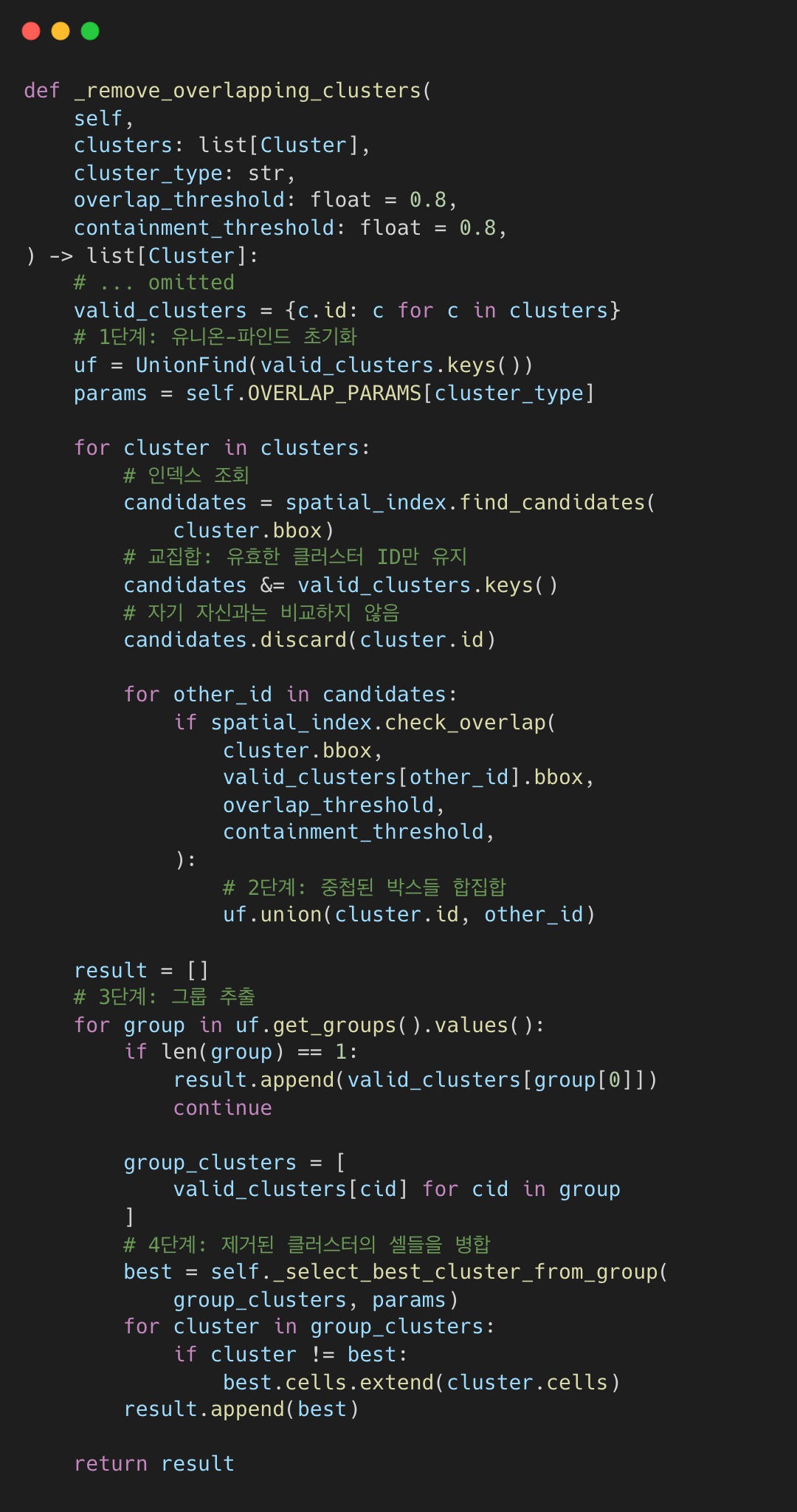
공간 인덱싱으로 효율적인 후보 발견이 가능하고, 유니온-파인드가 단일 패스로 그룹화를 처리한다.
효과
효율성: O(n²) 쌍별 비교를 선형에 근접한 공간 쿼리로 대체하여 수백만 개의 문서를 확장성 있게 처리한다.
품질: 감지 오류로 인한 중복 텍스트와 조각난 표를 제거하여 RAG와 후속 LLM 추론을 위한 깔끔한 데이터를 보장한다.
주요 기여자
이 기능에 대한 다른 주요 기여자가 있다면 알려주세요!