
[OpenClaw] 장시간 AI 에이전트 세션의 컨텍스트 보존을 위한 8가지 기법
Optimization · OpenClaw가 중요한 정보에 대한 컨텍스트를 잃지 않기 위해 사용하는 여러 방법에 대한 코드 분석

OpenClaw는 입소문을 타고 인기를 얻은 개인 AI 어시스턴트다. 자율적인 에이전틱 기능은 사용자들에게 획기적으로 다가왔다. 이 에이전트의 핵심은 바로 메모리다. 몇몇 사용자들은 OpenClaw가 “절대 잊지 않는다”고 말한다.
OpenClaw는 AI 에이전트가 중요한 컨텍스트를 마크다운 파일(MEMORY.md 또는 memory/YYYY-MM-DD.md)에 기록하게 함으로써 장기 메모리를 보존한다. 이 파일들은 이후 세션에 자동으로 로드된다. 이 글에서는 OpenClaw가 장시간 세션에서 메모리와 컨텍스트를 효과적으로 관리하기 위해 사용하는 8가지 기법을 살펴본다.
컴팩션 전 메모리 플러시 - 에이전트가 스스로 중요한 정보를 저장하게 한다
컨텍스트 윈도우 가드 - 한계에 도달하기 전에 미리 대응한다
도구 결과 가드 - 도구 호출 오류로 인한 트랜스크립트(transcript, 대화 기록) 오류를 방지한다
턴 기반 히스토리 제한 - 대화 중간이 아닌 턴(turn) 경계에서 자른다
캐시 인식 도구 결과 프루닝 - 속도와 비용 효율을 위해 모델 프로바이더 캐시를 존중한다
앞/뒤 콘텐츠 보존 - 시작과 끝을 유지하고 중간을 생략한다
적응형 청크 비율 - 다양한 메시지 크기를 유연하게 처리한다
단계적 요약 - 오버플로우를 피하기 위해 청크 단위로 나눠 요약한다
아래 다이어그램은 컨텍스트 관리 기법들의 상호작용을 단순화하여 보여준다.

아래 진입점은 별도의 에이전트 실행으로 턴(turn) 수행 전에 메모리 플러시(기법 1)를 수행할 수 있다. 이것이 완료되거나 건너뛰어진 후에야 메인 에이전트 턴이 시작된다.

메인 턴 동안 OpenClaw는 가드(guard)를 적용하고 필요할 때 컴팩션(compaction, 압축)을 트리거한다.
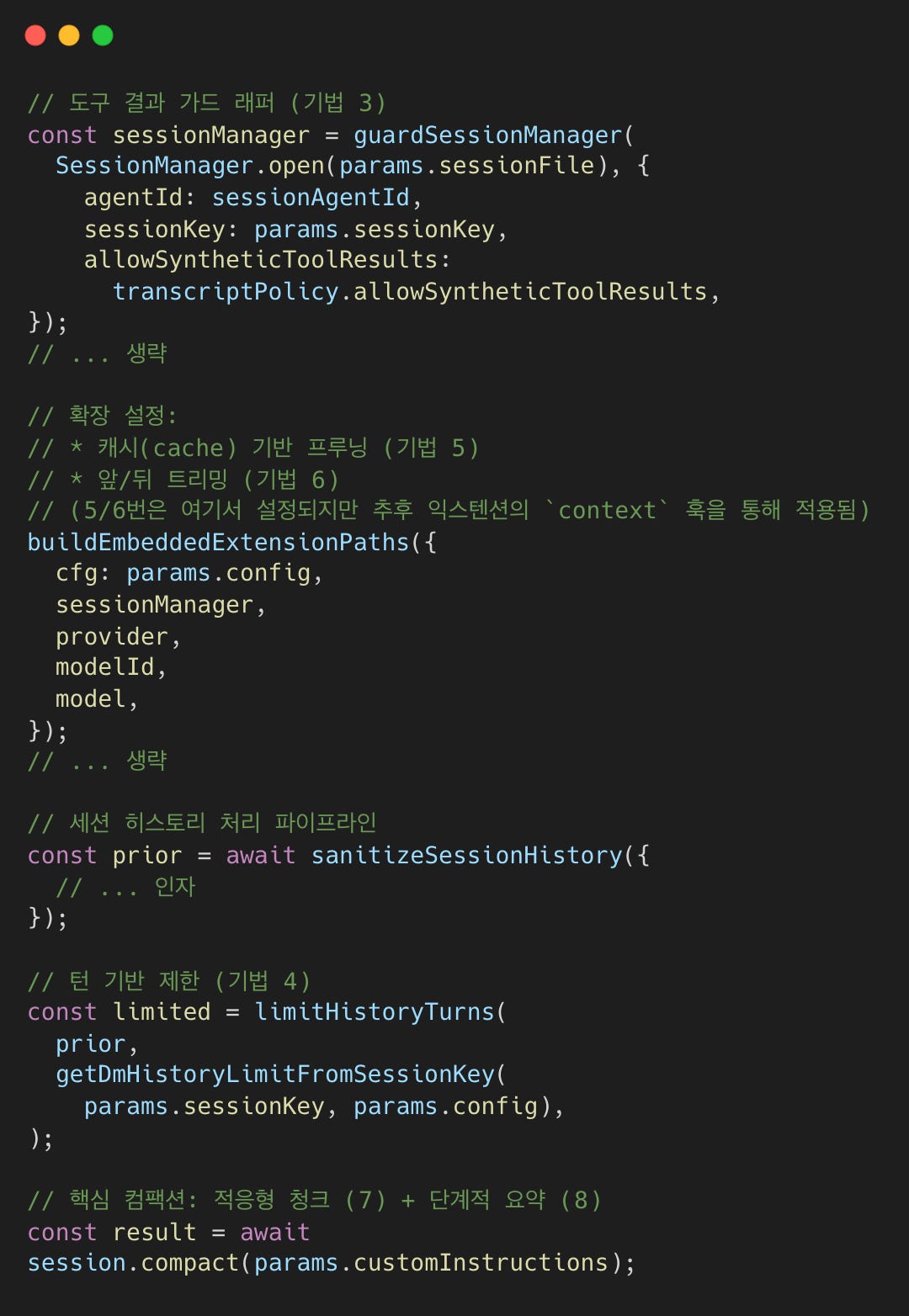
기법 1: 컴팩션 전 메모리 플러시
세션이 컴팩션 단계에 가까워지면, OpenClaw는 대화 히스토리가 온전할 때 에이전트가 영구적인 노트를 디스크에 기록할 수 있도록 ‘턴 전 메모리 플러시(flush)’를 실행한다. 이는 사용자에게 보이지 않게 실행된다.
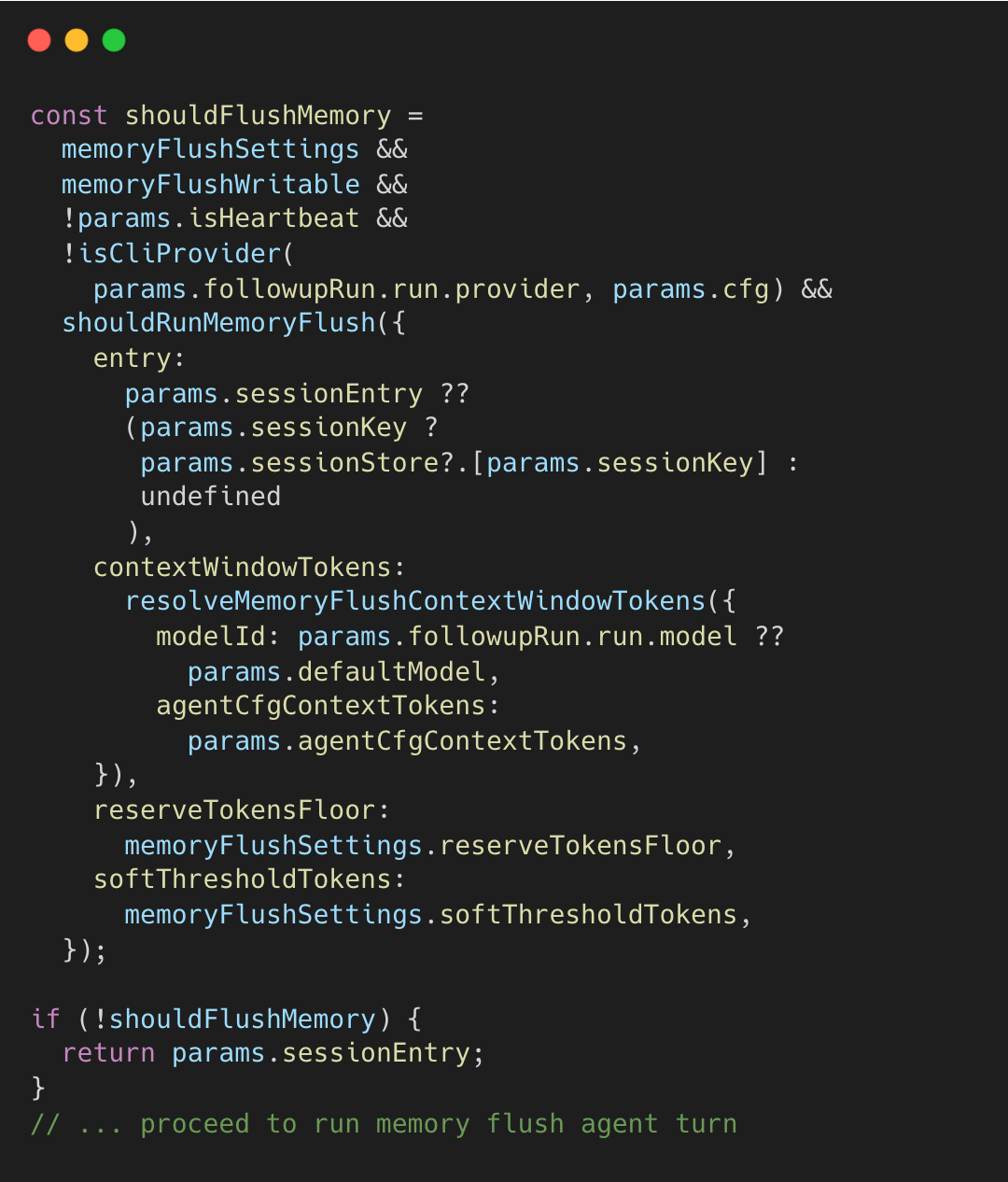
shouldFlushMemory가 참이면 추가 턴을 실행하고, 그렇지 않으면 메인 턴으로 바로 진행한다. 결정 로직은 다음과 같다.
구현 코드는 아래와 같다.

컴팩션은 사이클당 1회로 제한되는데, memoryFlushCompactionCount를 확인하여 방지한다.
플러시가 실행될 때, 프롬프트는 에이전트에게 기록할 위치를 알려주고, 저장할 내용이 없으면 조용히 종료하도록 지시한다.
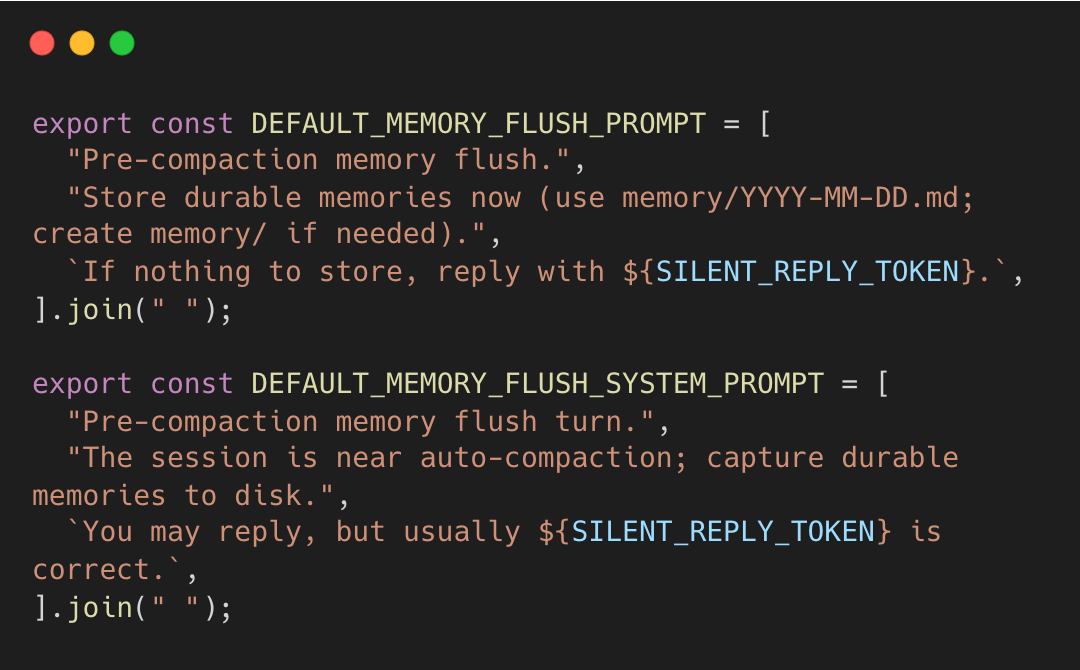
무엇을 기억할지는 정해진 규칙이 아니라 에이전트가 직접 결정한다. 에이전트가 MEMORY.md에 사실을 기록하면, 이는 이후 세션에 다시 주입된다. 세션 컨텍스트와 영구 저장소 사이에 피드백 루프가 형성된다.
기법 2: 컨텍스트 윈도우 가드
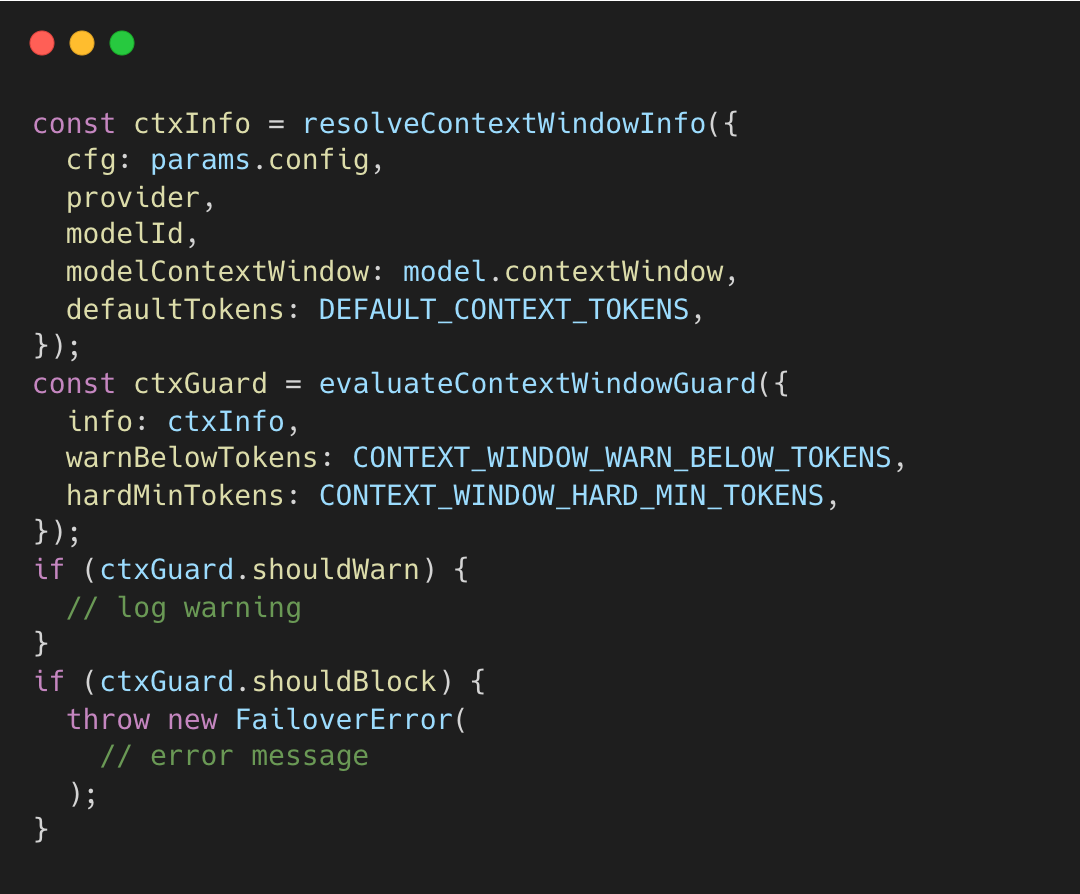
OpenClaw는 모델의 컨텍스트 윈도우 용량을 검증하는 ‘프리플라이트(pre-flight)’ 가드를 실행한다. 세션이나 턴이 시작되기 전에 시스템은 모델의 컨텍스트 윈도우 크기(예: Opus 4.5의 경우 200K)를 확인한다.
ctxInfo.tokens는 선택된 모델의 컨텍스트 윈도우를 나타낸다.
컨텍스트 윈도우 값은 모델이 충분히 큰지 확인하기 위해 안전 임계값과 비교된다.
하드 최소값 (16K 토큰): 모델의 윈도우가 이보다 작으면 OpenClaw은
FailoverError를 던진다. 에이전트가 완료할 수 없는 작업을 시작하는 것을 방지한다.경고 임계값 (32K 토큰): 윈도우가 16K에서 32K 사이일 경우 세션 공간이 부족할 수 있다는 경고를 남기지만, 실행 자체는 허용한다.
context-window-guard.ts#L57-L74

기법 3: 펜딩 플러시를 통한 도구 결과 가드
LLM API는 모든 tool_call에 대해 그에 상응하는 tool_result가 반환되기를 기대한다. 도구가 실행 중 타임아웃되거나 크래시하면 세션에 결과를 받지 못한 도구 호출이 남게 되고, 이로 인해 다음 API 요청이 실패하거나 모델이 결과를 할루시네이션할 수 있다.
가드는 세션 시작 시 SessionManager를 래핑하여 호출 ID를 전부 추적하고, 도구 결과가 오기 전에 사용자 메시지가 도착하면 가드가 합성 플레이스홀더를 주입한다. 이 로직은 컴팩션 중에도 적용되며, guardSessionManager가 appendMessage 호출을 가로채서 완료되지 않은 도구 호출을 해결한다.

이 플레이스홀더는 도구 호출 문제 발생시 API 오류를 막고, 모델에게 도구 실행이 불완전했음을 알린다. makeMissingToolResult 구현은 주입되는 정확한 에러 메시지를 보여준다.
session-transcript-repair.ts#L48-L65

가드는 세션 트랜스크립트(메시지 히스토리)에 대한 appendMessage 호출을 가로챈다. 도구 호출이 완료되지 않은 상태에서 도구 결과가 아닌 다른 메시지가 도착하면 우선 합성(syntehtic) 결과를 플러시한다.
session-tool-result-guard.ts#L79-L132
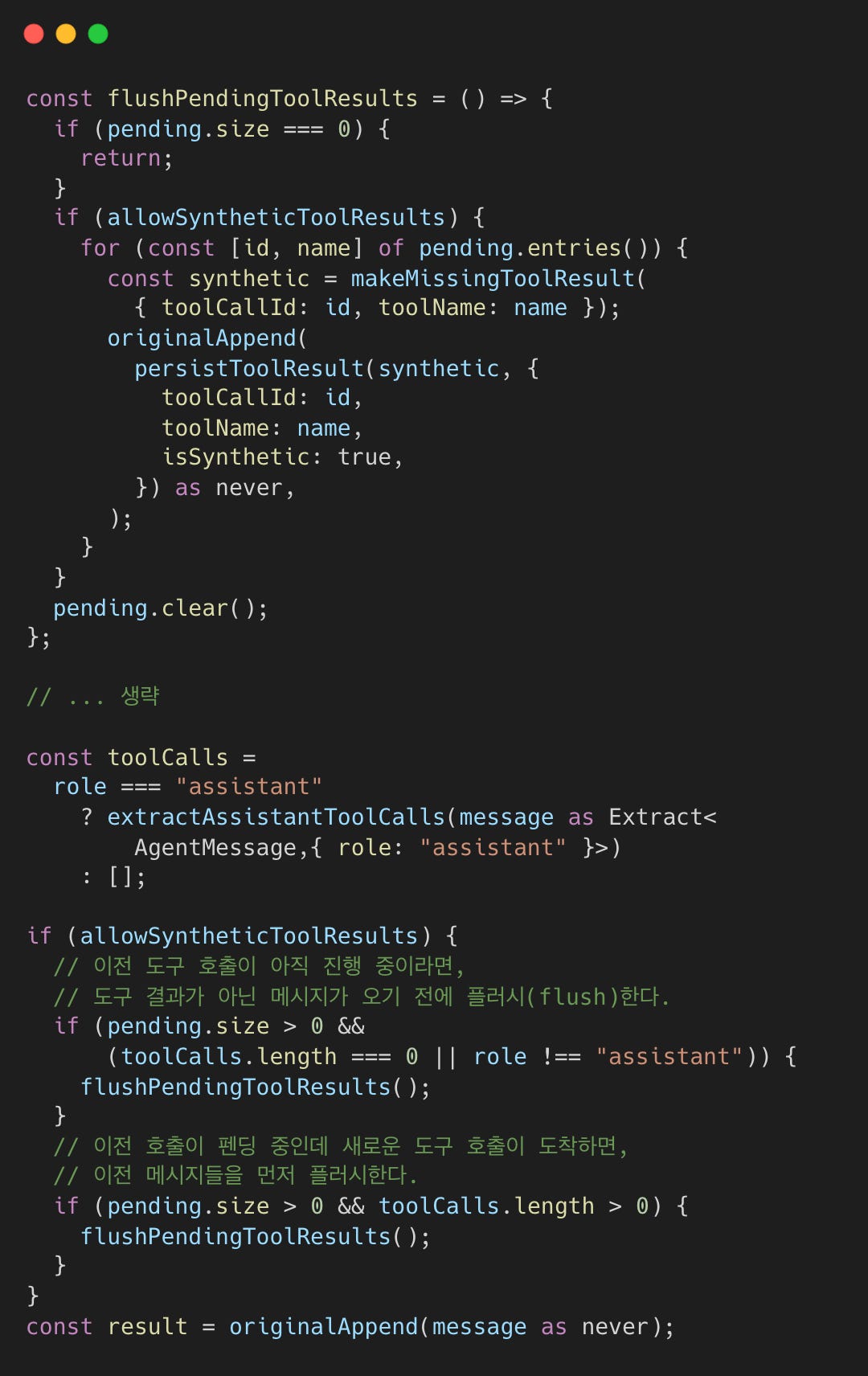
이로써 어시스턴트의 도구 호출이 짝을 찾지 못해 트랜스크립트가 손상되는 것을 방지한다. 합성 결과에는 도구 호출이 불완전했음을 알리는 플레이스홀더 콘텐츠가 포함된다.
기법 4: 턴 기반 히스토리 제한
채팅 히스토리를 프롬프트에 포함할 때 단순히 메시지 개수로 제한하면, 대화 구조가 무시되어 문맥이 끊길 수 있다. OpenClaw는 이를 방지하기 위해 사용자 턴(turn) 단위로 대화 내역을 제한한다.
세션 히스토리를 정제하고 검증한 후 파이프라인은 턴 기반 제한을 적용한다.
openclaw/openclaw:attempt.ts:L541-L554
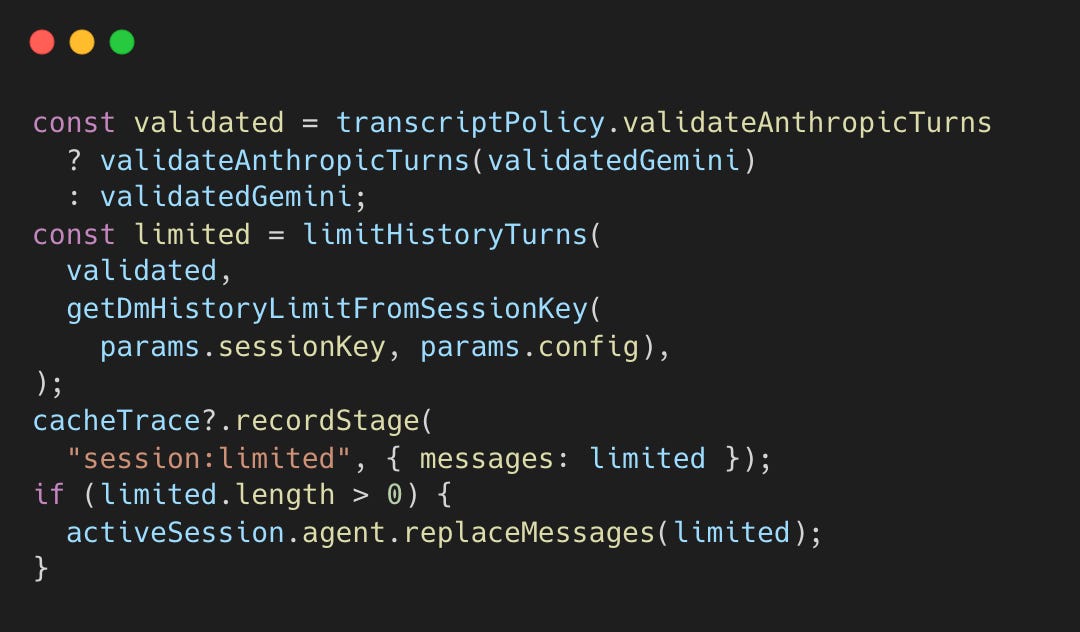
이 방식은 대화 중간이 아닌 명확한 경계(사용자 메시지)에서 잘리도록 보장한다.
openclaw/openclaw:history.ts:L11-L36
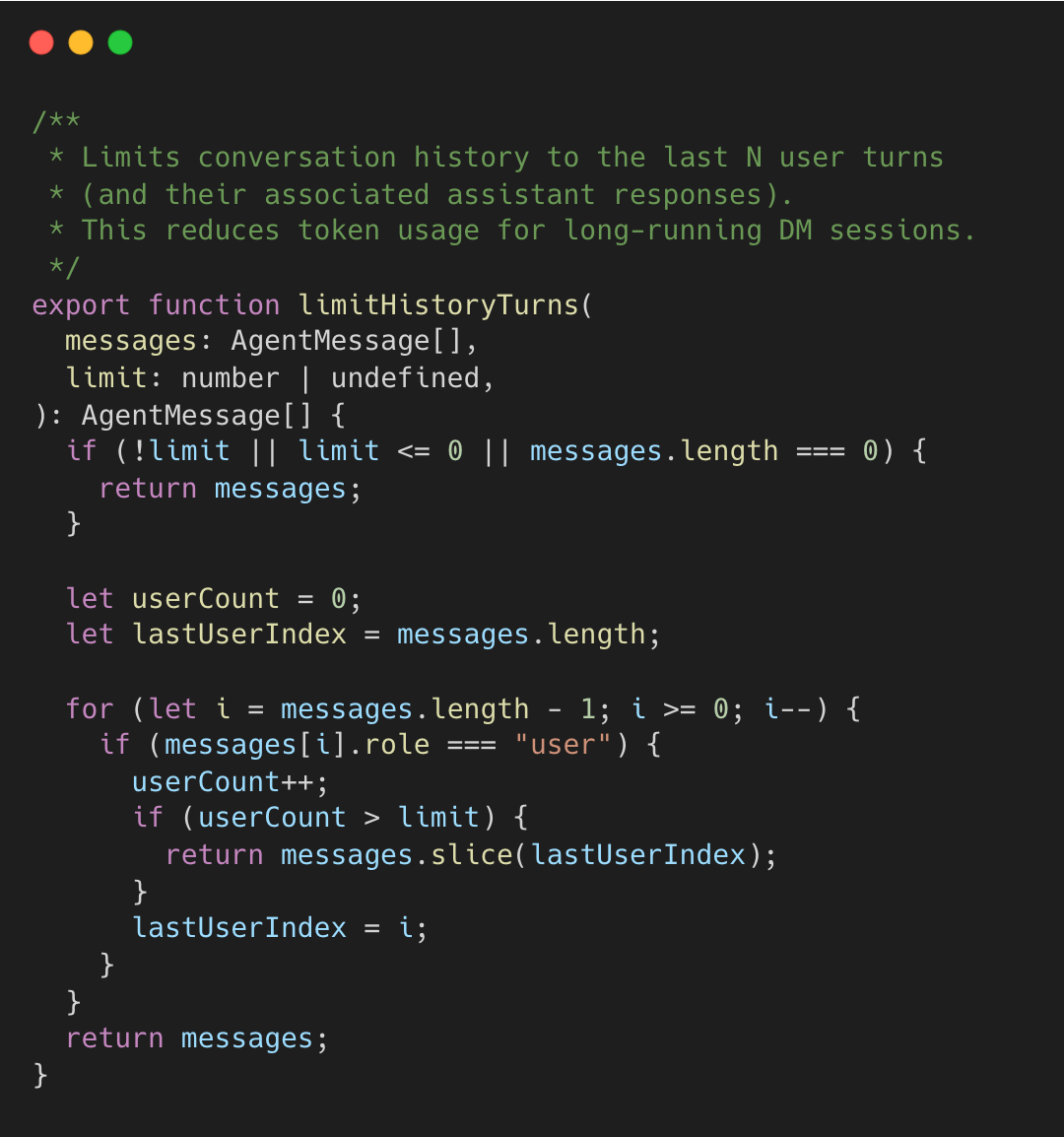
알고리즘은 뒤에서부터 사용자 턴을 세며, 제한에 도달하면 해당 사용자 메시지를 기준으로 자른다. DM 세션은 우선순위가 높은 사용자에게 더 긴 히스토리를 유지하기 위해 사용자별 제한 설정을 허용한다.
기법 5: 캐시 인식 도구 결과 컨텍스트 프루닝
Claude나 Gemini 같은 LLM 제공업체는 서버 측에서 프롬프트 프리픽스(prefix)를 캐싱하지만, 애플리케이션이 언제 이를 변경할지는 예측하지 못한다. 세션 중간에 앞쪽 메시지가 수정되면, 제공업체는 전체 프롬프트를 처음부터 다시 처리해야 한다. 애플리케이션 레벨의 프루닝은 로컬에서 캐시 타이밍을 추적하여 이 문제를 해결한다. 캐시가 유효한 동안은 앞부분을 유지하고, 캐시가 만료되었을 때 프루닝을 수행한다.

프루닝 익스텐션은 세션 설정 중 초기화된다. 세션이 익스텐션 경로를 빌드할 때 다른 익스텐션들과 함께 컨텍스트 프루너를 등록한다. 이 익스텐션은 에이전트 프레임워크의 “context” 이벤트를 사용하며, 이는 LLM API 호출 직전에 발생하여 메시지 전송 전 프루닝할 기회를 제공한다.

프루너는 ‘소프트 트림(앞/뒤 보존)’과 ‘하드 클리어(플레이스홀더로 교체)’ 이렇게 두 가지 프루닝을 제공한다.
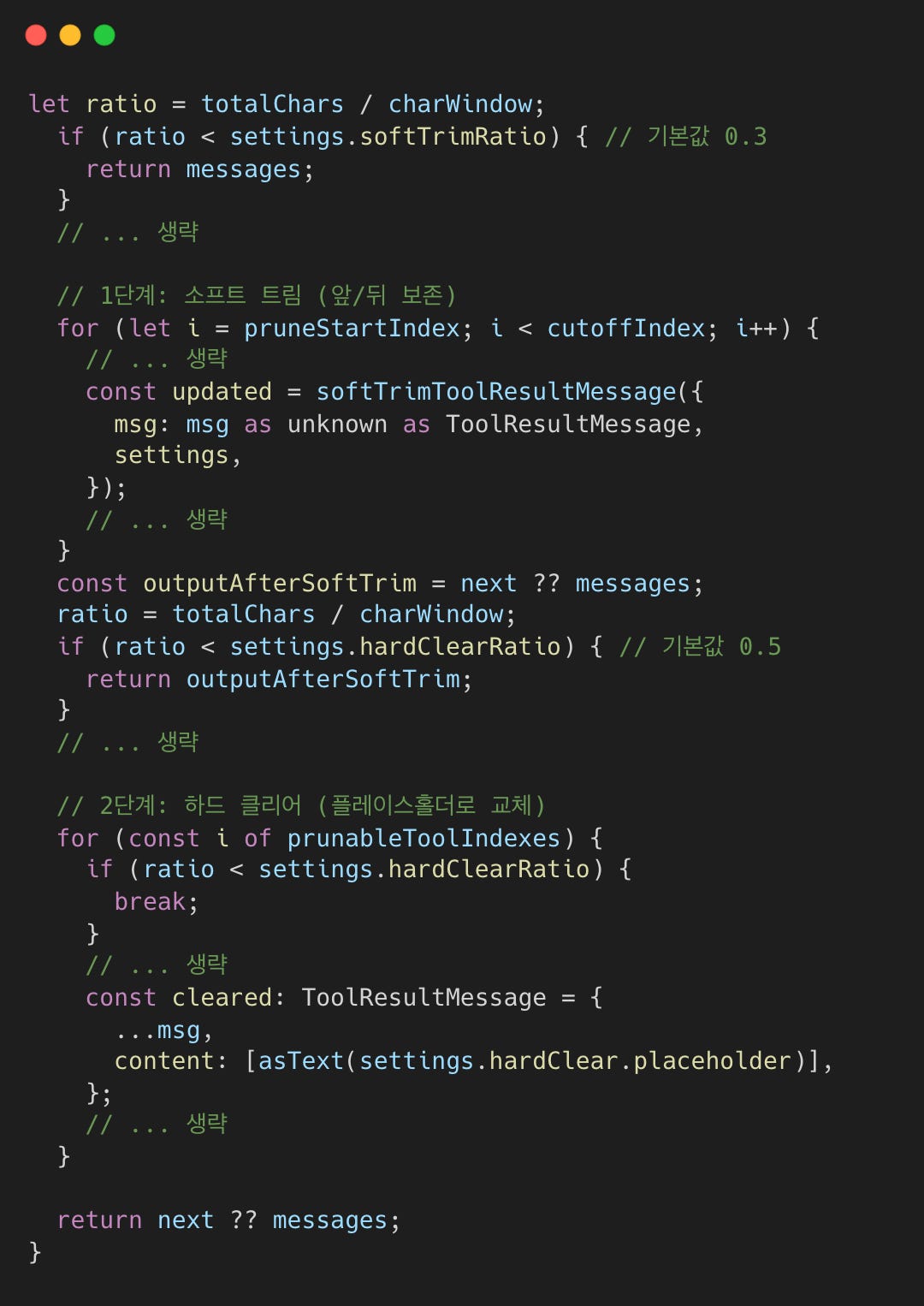
프루닝은 컨텍스트 사용량이 설정된 안전 임계값에 도달할 때만 실행된다.
> 30% (소프트 트림): 앞과 뒤만 유지하여 도구 결과의 크기를 줄인다(기법 6).
> 50% (하드 클리어): 최대 공간을 확보하기 위해 도구 결과 전체를 간단한 플레이스홀더(placeholder)로 교체한다.
최근 대화 흐름을 유지하기 위해, 어시스턴트의 마지막 턴 세 개는 항상 프루닝 대상에서 제외된다. 소프트 트림 단계는 보통 중요한 정보를 담고 있는 시작과 끝을 유지하면서 메시지 크기를 줄이기 위해 기법 6을 활용한다.
기법 6: 앞/뒤 맥락 보존
메시지의 뒷부분만 단순히 잘라내면, 에러 메시지처럼 중요한 정보를 놓칠 수 있다. 이를 해결하기 위해 OpenClaw는 앞부분과 뒷부분을 모두 보존하는 방식을 취한다.
컨텍스트 프루닝 과정에서 도구 결과가 4,000자를 초과하면 ‘소프트 트림’이 적용된다. 기본 설정은 처음 1,500자(앞)와 마지막 1,500자(뒤)를 남기는 것이다.
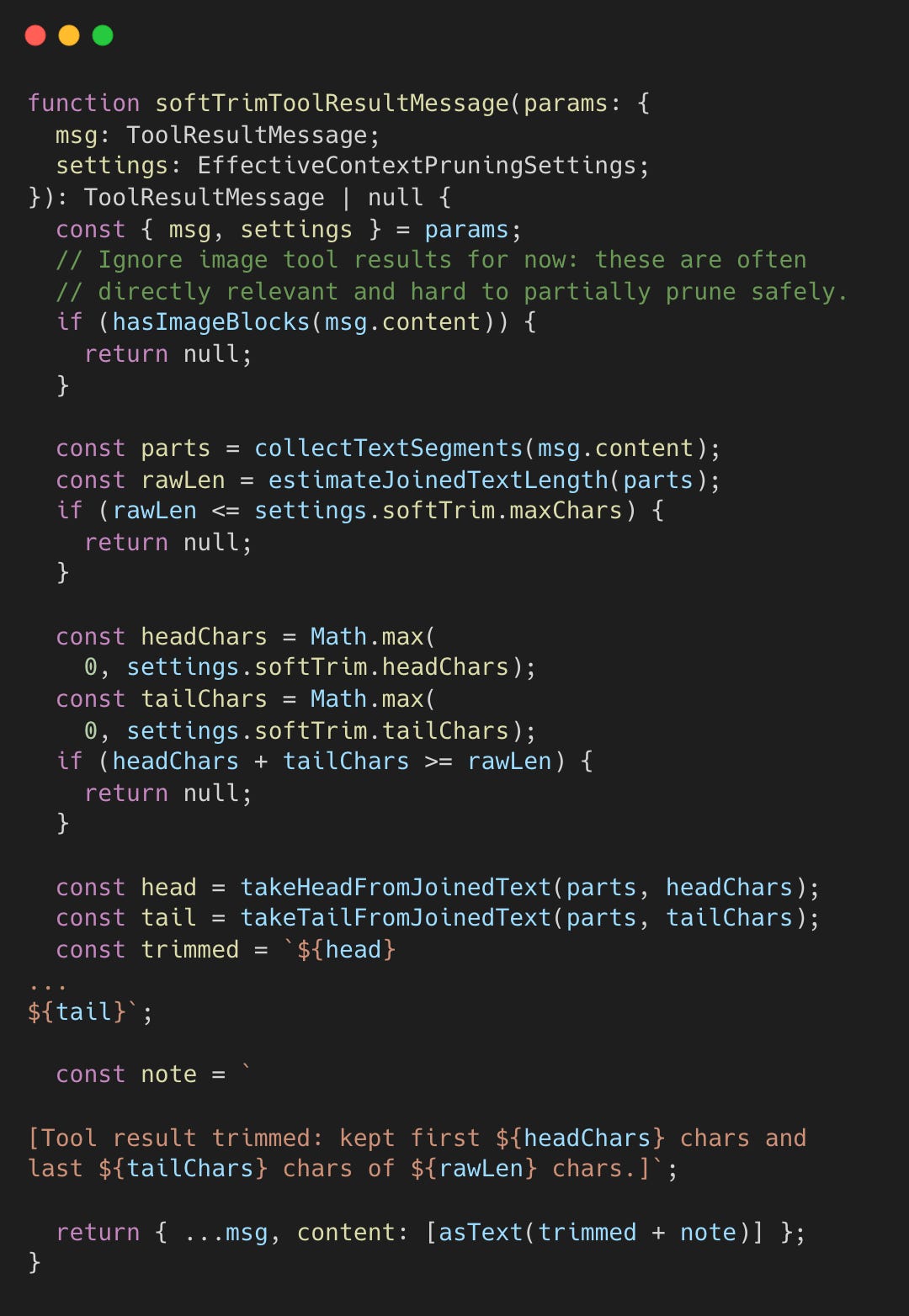
에이전트 성격을 정의하는 SOUL.md나 사용자 선호도를 담은 USER.md 같은 부트스트랩 파일은 세션 시작 시 주입되어 아이덴티티와 컨텍스트를 설정한다. 부트스트랩 파일은 70/20 비율로 잘리는데, 이는 핵심 지침이 포함된 시작 부분(70%)을 우선하되 최근 업데이트 내용인 뒷부분(20%)도 놓치지 않기 위함이다. 나머지 10%는 생략되었음을 알리는 마커(marker) 공간으로 사용된다.

기법 7: 적응형 청크 비율
메시지 크기가 다양할 때, 고정된 청크(chunk) 크기는 비효율적이다. 10K 토큰에 달하는 코드 블록은 짧은 대화 메시지와는 다른 방식으로 처리되어야 한다.
핵심은 각 요약 청크의 크기를 잘 결정하는 것이다. 청크가 너무 크면 요약 요청 시 컨텍스트 윈도우를 초과할 위험이 있고, 반대로 너무 작으면 불필요한 API 호출이 늘어난다. ‘적응형 비율’ 방식은 청킹(chunking) 전에 실제 메시지 크기를 분석하여 최적의 비율을 결정한다.
compaction-safeguard.ts#L271-L275

계산된 비율은 컨텍스트 윈도우 크기에 곱해져 maxChunkTokens, 즉 요약 청크 하나당 허용되는 최대 토큰 수가 된다. 200K 컨텍스트 윈도우에서 비율 0.4면 청크는 80K 토큰으로 제한된다. 메시지 평균 크기가 컨텍스트 윈도우의 15%를 넘으면, 요약 결과가 들어갈 공간을 확보하기 위해 비율을 0.25로 낮춰 청크 크기를 50K 토큰으로 제한한다.

기법 8: 폴백을 통한 단계적 요약
긴 대화를 한 번에 요약하면 컨텍스트 윈도우 한도를 초과할 수 있다.
컴팩션 세이프가드는 드롭된 메시지(크기로 인해 프루닝됨), 메인 히스토리, 분할된 턴 접두사 세 지점에서 단계적 요약을 적용한다. 입력이 청크 제한을 넘으면, 각 단계에서 재귀적으로 추가 분할이 이루어질 수 있다.
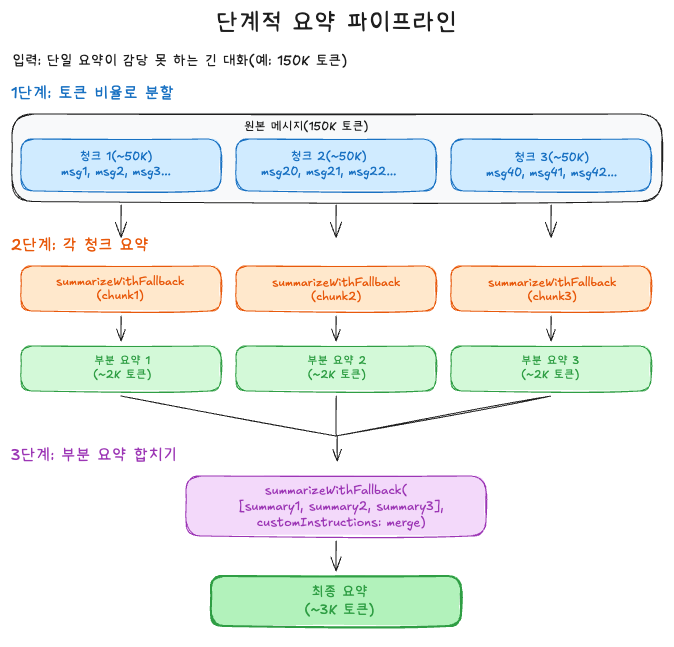
단계적 요약 구현은 아래와 같다.
결론
8가지 기법이 어우려저 수 시간에서 며칠에 이르는 긴 세션의 중요한 컨텍스트를 보존한다. 에이전트에게 데이터를 저장할 시간을 주는 ‘메모리 플러시’ 패턴은, 컴팩션(압축) 과정을 단순한 ‘컨텍스트 손실’이 아닌 ‘의사결정 아카이빙’의 기회로 전환한다.
OpenClaw는 컨텍스트를 단순한 텍스트가 아닌, 메모리처럼 관리해야 할 핵심 자원으로 다룬다. ‘메모리’ 사용량 급증에 대비해 다중 계층의 최적화와 안전장치(fallback)를 마련했다.
예방: 컨텍스트 가드로 예기치 않은 오류를 방지한다 (기법 2)
보존: 메모리 플러시로 에이전트의 의도를 보존한다 (기법 1)
적응: 적응형 청킹(기법 7)과 턴 기반 제한(기법 4)으로 다양한 상황에 유연하게 대처한다
최적화: 캐시 인식 프루닝(기법 5)과 앞/뒤 트리밍(기법 6)으로 비용과 의미를 모두 잡는다
견고성: 도구 결과 가드(기법 3)와 단계적 요약(기법 8)으로 트랜스크립트 손상과 엣지 케이스를 막는다
주요 기여자
Staged Helpers by @steipete (Peter Steinberger)
Tool-result Context pruning by @maxsumrall (Max Sumrall)
Pre-compaction Memory flush by @steipete (Peter Steinberger)
Compaction safeguard by @steipete and @thewilloftheshadow (Shadow)