
[x-algorithm] X/트위터가 5억 5천만 사용자의 피드를 결정하는 방법
Deep Dive · 2026년 1월 20일 X가 오픈소스로 공개한 피드 알고리즘 코드 분석

아키텍처
CandidatePipeline 프레임워크는 추천 단계들의 상호작용을 정의하는 모듈로 이루어져 있다.
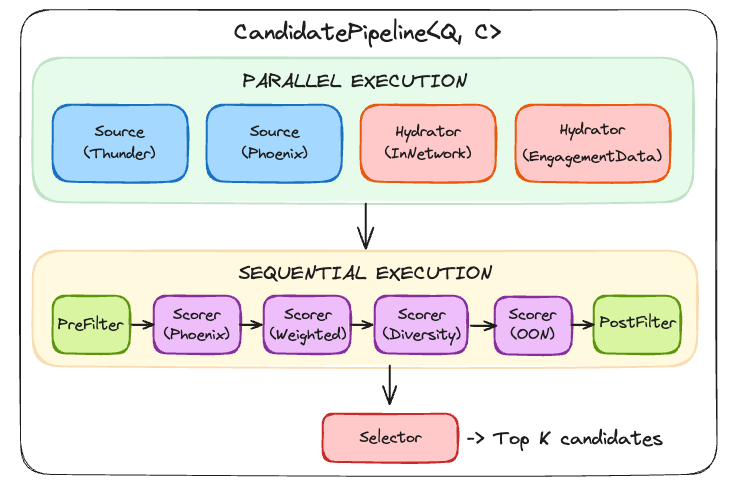
핵심 컴포넌트는 다음과 같다.
Sources: 후보 게시물을 수집한다. Thunder는 팔로우 중인 계정(In-network)에서, Phoenix는 전체 플랫폼에서 ML 유사도로 관련 게시물(Out-of-network 및 In-network)을 찾는다.
Hydrators: 후보에 메타데이터(인게이지먼트 통계, 작성자 정보 등)를 보강한다.
Scorers와 Filters: 보강된 후보를 평가하고 정제한다.
파이프라인 실행 모델
CandidatePipeline 트레이트가 인터페이스를 정의하며, PhoenixCandidatePipeline 같은 구현체가 컴포넌트들을 연결한다.
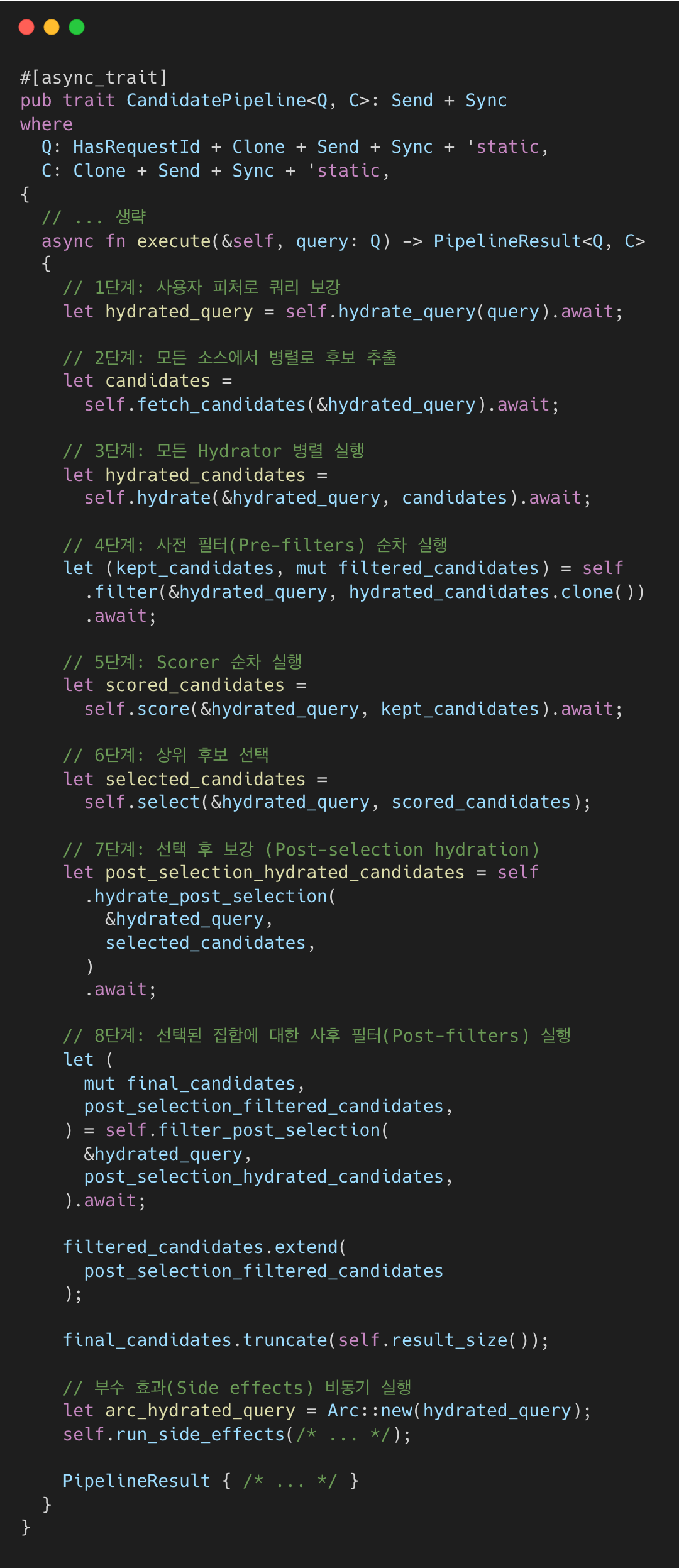
For You 탭을 열면 서버는 요청마다 전체 파이프라인을 실행한다.
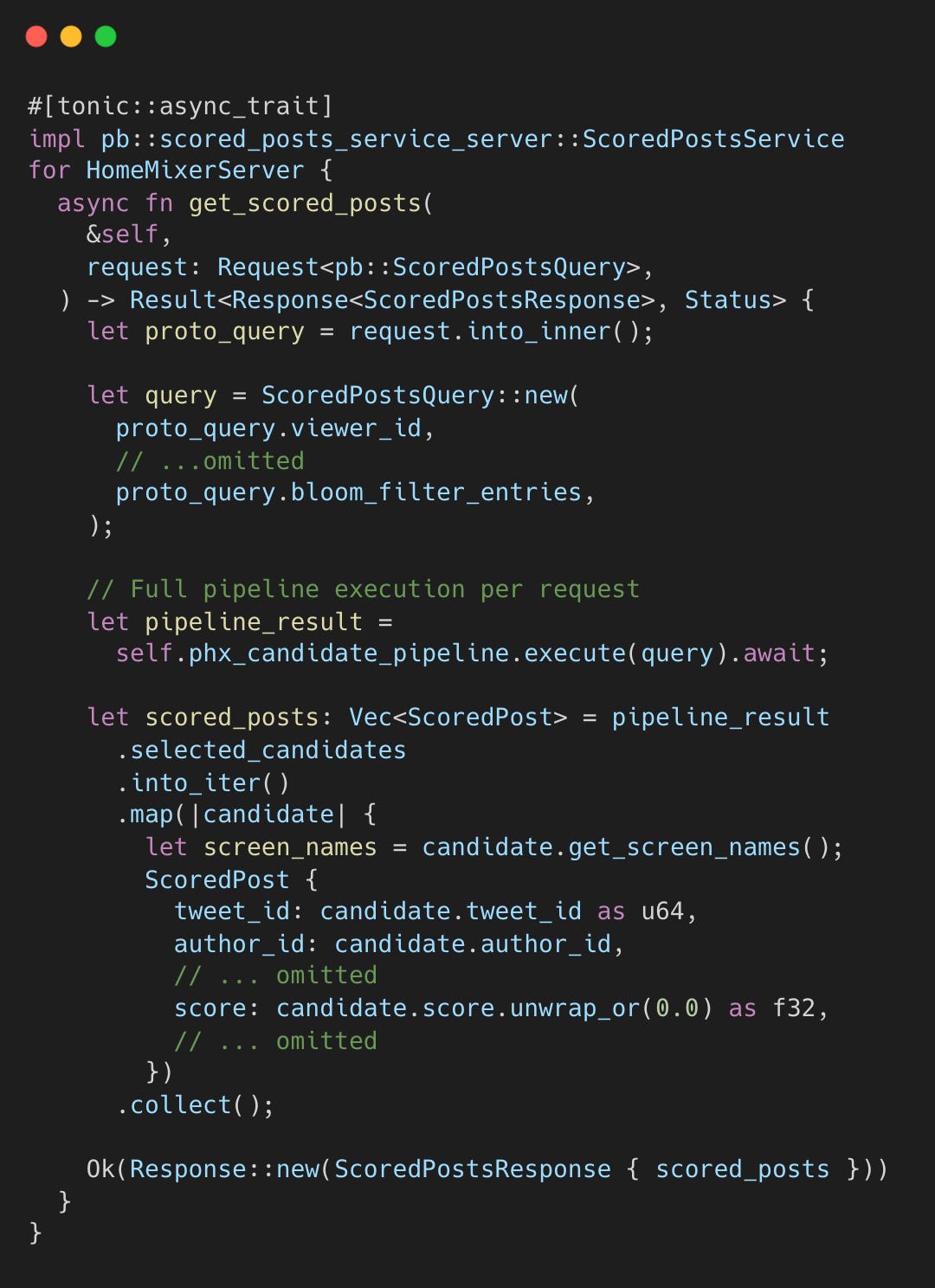
Phoenix Scorer는 Grok 기반 트랜스포머로 인게이지먼트를 예측한다. 호출될 때마다 고유 ID와 타임스탬프를 생성한다.
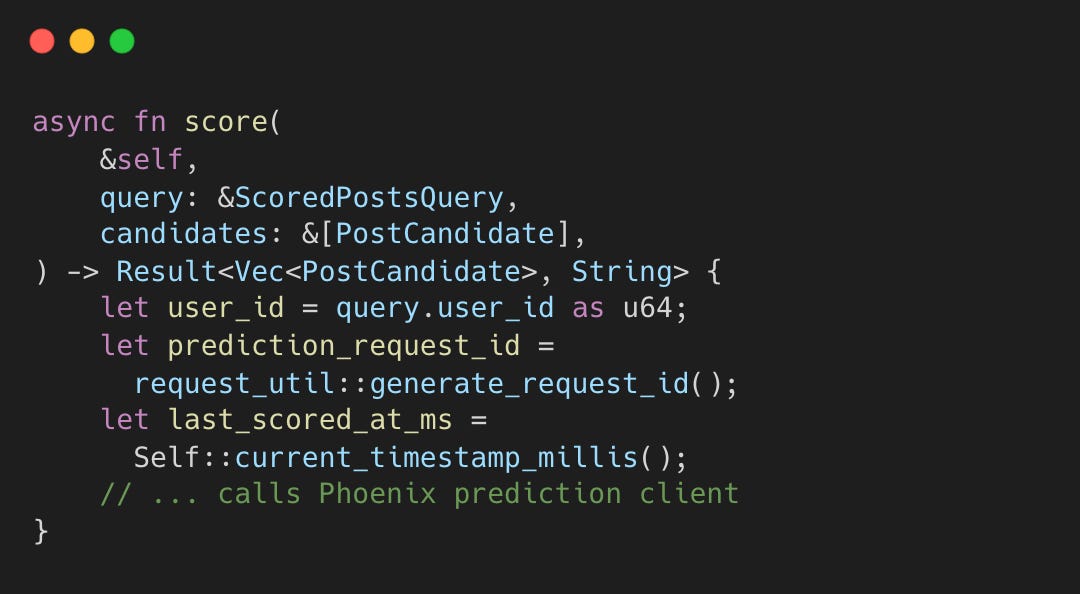
게시물의 점수는 동적이다. 같은 게시물이라도 1시간 뒤 조회수와 좋아요가 늘어나면 Phoenix는 다른 예측값을 내놓는다.
Stage 1: 후보 추출 (Retrieval)
Retrieval의 목표는 수백만 개의 거대 corpus를 랭킹 가능한 수천 개 수준으로 좁히는 것이다.
In-network: 팔로우한 계정의 게시물 (점수 보존).
Out-of-network (OON): 관심사 기반 발견 게시물 (랭킹 시 페널티 적용).
두 가지 주요 Source인 Thunder와 Phoenix가 이를 담당한다.
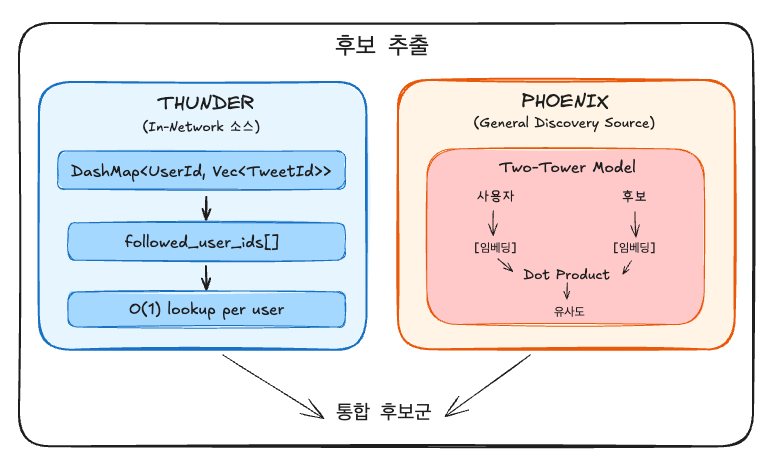
Thunder: In-Network 콘텐츠
Thunder는 지난 48시간의 트윗을 인메모리 DashMap에 저장하고 제공하는 서비스다. home-mixer는 gRPC로 Thunder를 쿼리한다.
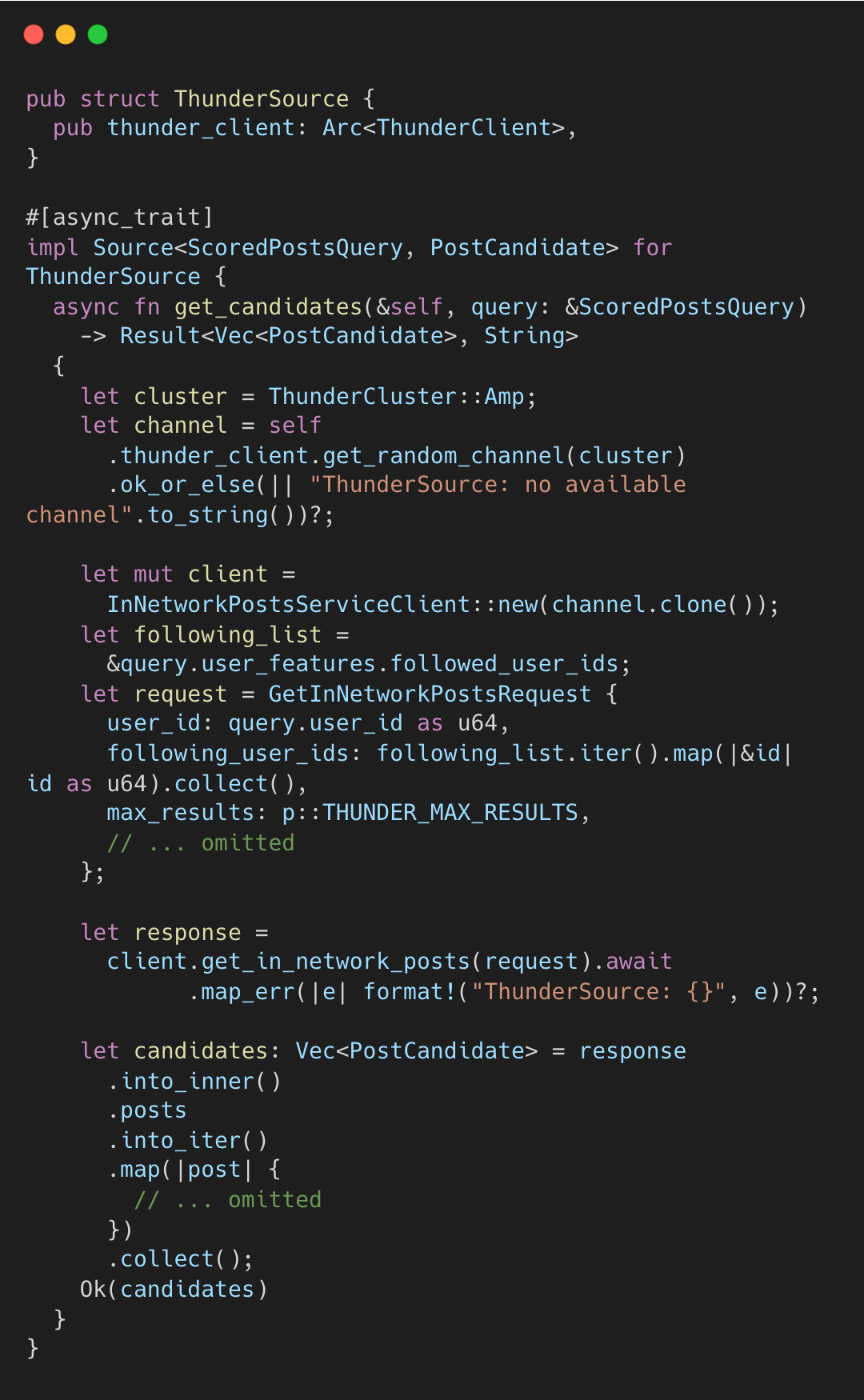
Thunder의 PostStore는 원본, 답글/리트윗, 비디오 인덱스를 분리하여 O(1) 조회를 지원한다.
thunder/posts/post_store.rs#L36-L53
Phoenix: 발견 (Discovery)
Phoenix는 Two-Tower 신경망 구조를 사용해 사용자와 게시물을 매칭한다.
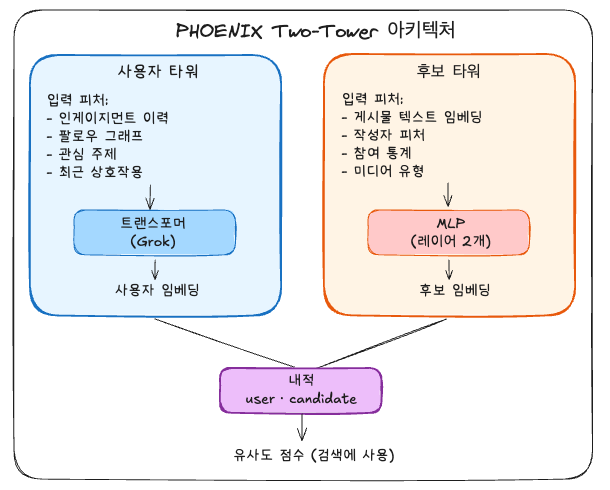
User Tower: 트랜스포머 + 평균 풀링
User Tower는 사용자 피처와 활동 이력을 Grok 트랜스포머에 입력하고 평균 풀링(Mean Pooling)하여 사용자 임베딩을 생성한다.
recsys_retrieval_model.py#L206-L276
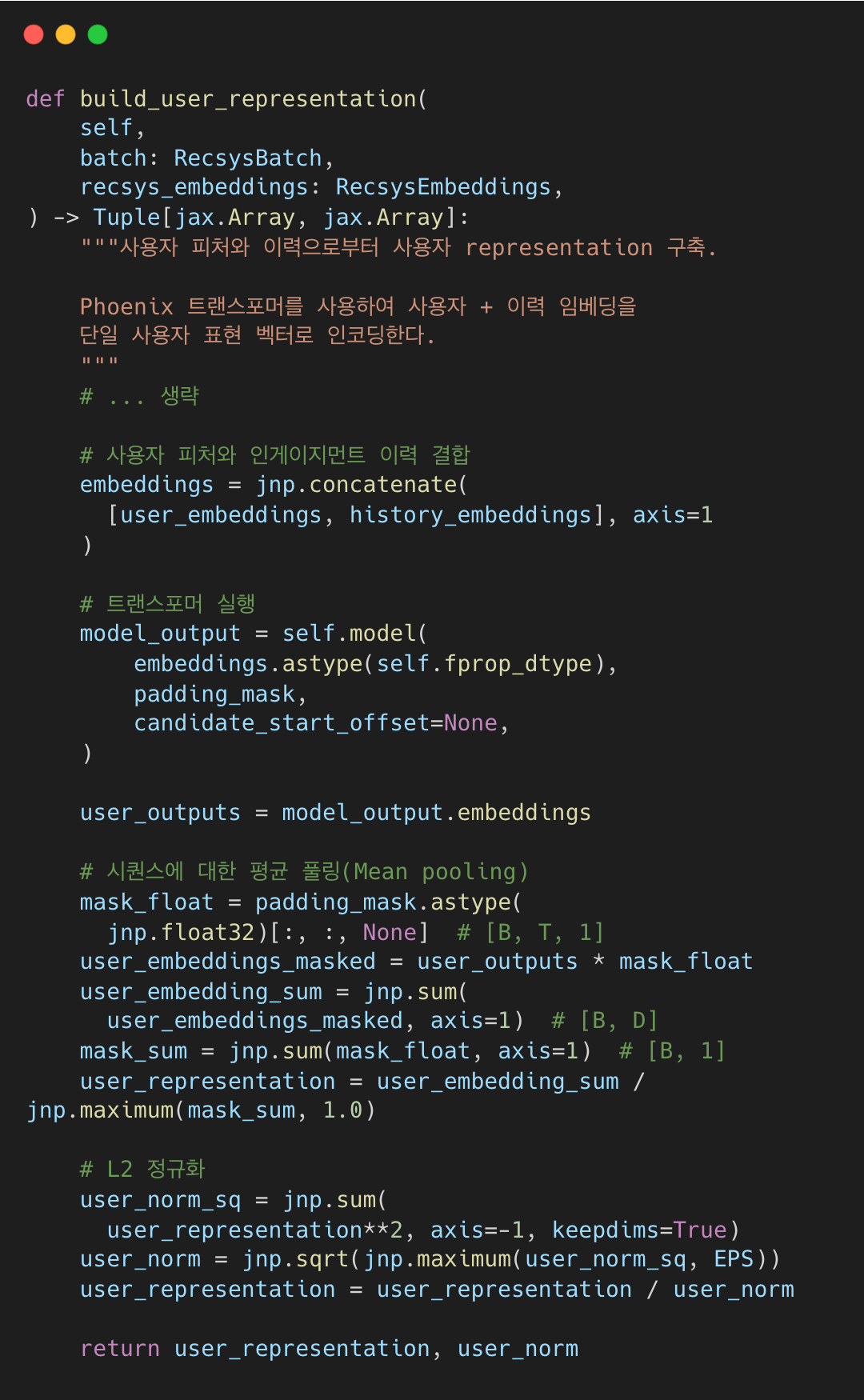
Candidate Tower: 2층 MLP
Candidate Tower는 게시물과 작성자 임베딩을 공유 공간으로 투영하는 간단한 레이어 2개 MLP(SiLU 활성화) 구조다.
recsys_retrieval_model.py#L47-L99
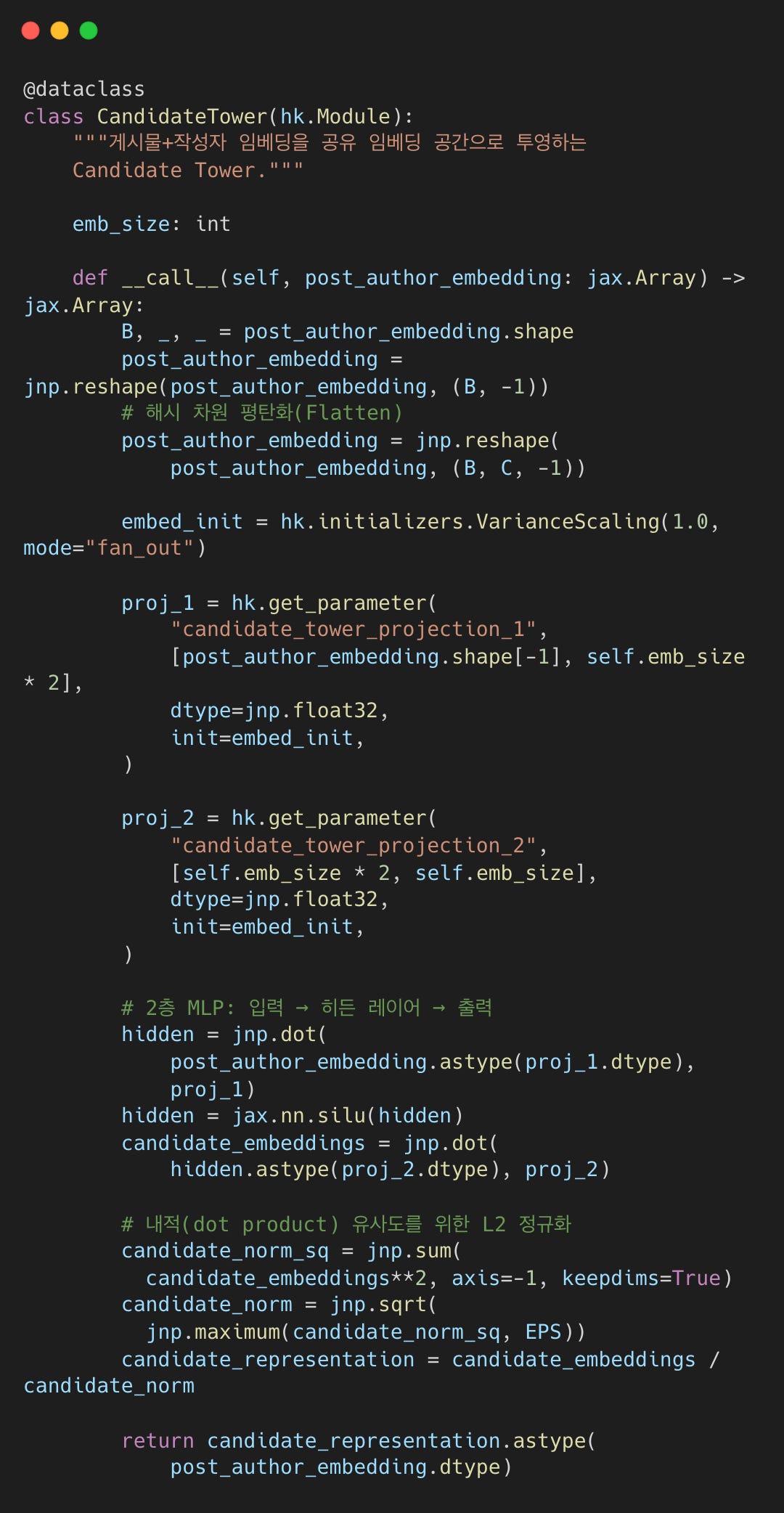
Retrieval: 내적(Dot Product) 유사도
L2 정규화된 임베딩 간의 내적은 코사인 유사도와 같다.
recsys_retrieval_model.py#L346-L372
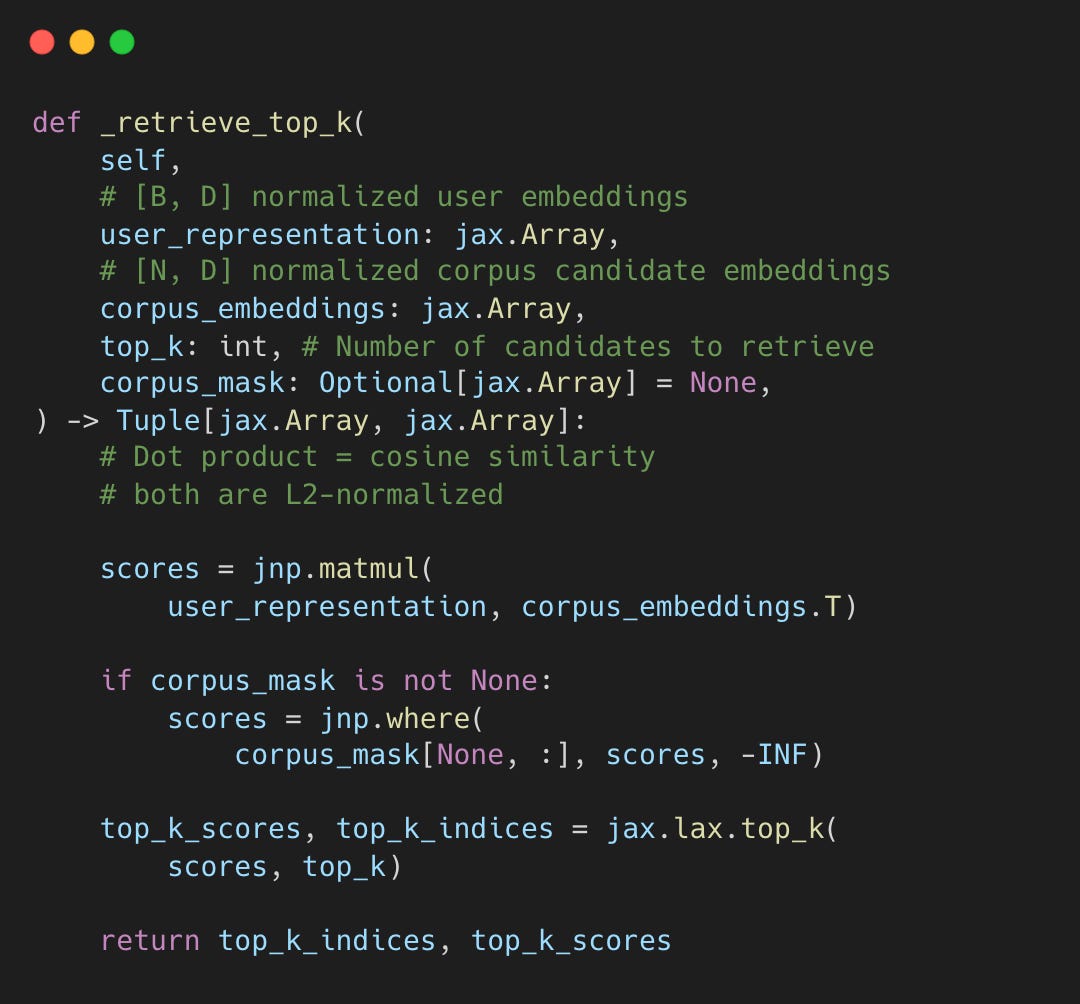
Phoenix는 요청 시점에 사용자 임베딩을 생성하고, ANN(근사 최근접 이웃) 인덱스를 통해 미리 계산된 수백만 후보 중 Top-k를 빠르게 찾는다.
Stage 2: 네트워크 분류 (In-Network vs Out-of-Network)
점수 산정 전, InNetworkCandidateHydrator가 게시물의 출처를 분류한다. Phoenix(발견)가 팔로우 중인 계정의 게시물을 추천할 수도 있기 때문에, 이를 명확히 In-network로 마킹하여 페널티를 방지한다.
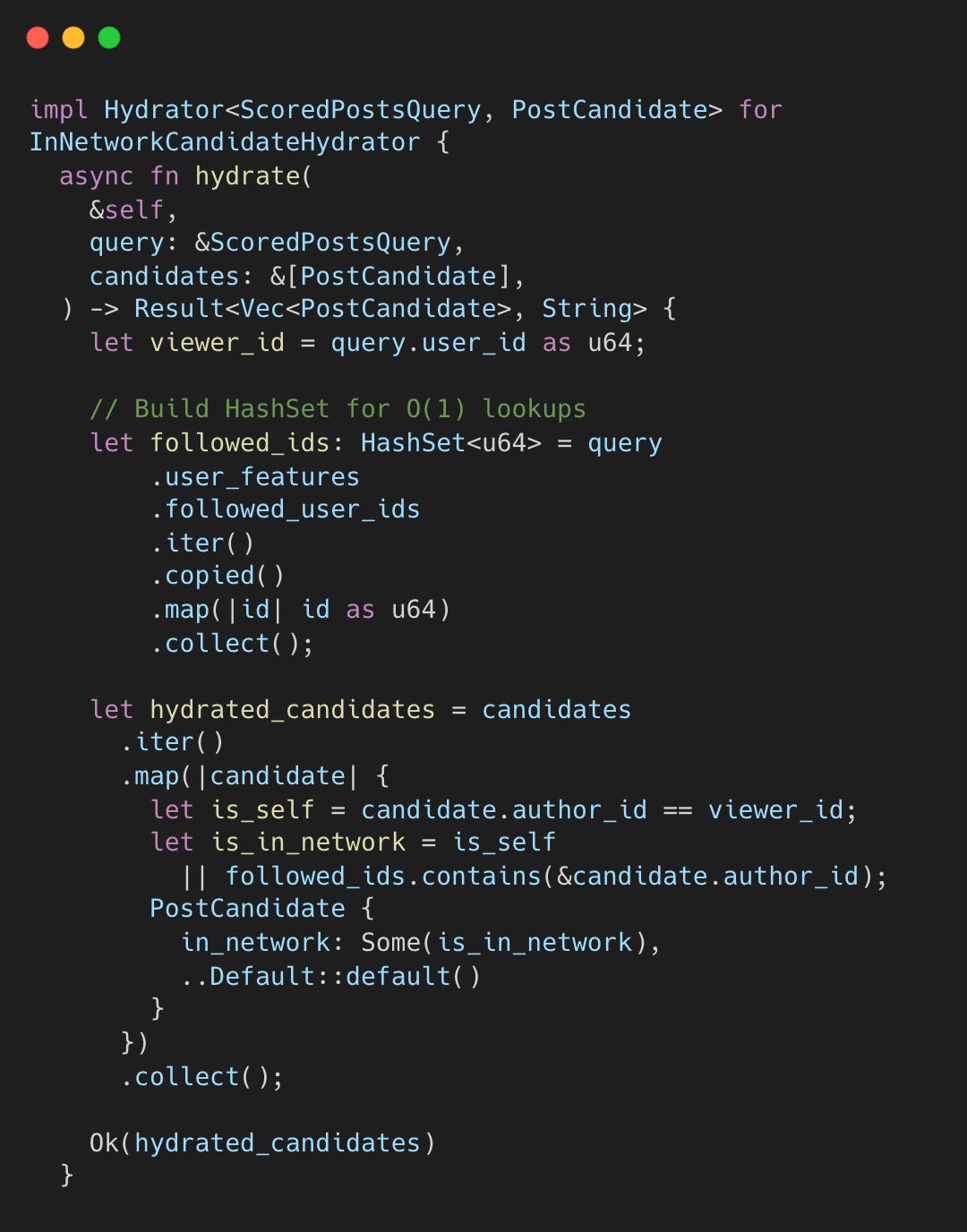
in_network 플래그는 이후 단계의 점수 산정과 필터링 로직에 핵심적인 영향을 미친다.
왜 분류기를 사용할까? Phoenix는 때로 팔로우한 계정의 게시물을 반환할 수 있다. hydrator는 팔로우한 계정의 모든 게시물이 Thunder(구독)에서 왔든 Phoenix(발견)에서 왔든 “in-network” 상태를 얻도록 보장한다.
불리언 플래그 in_network는 파이프라인을 통해 전파되어 점수 산정과 필터링에 영향을 미친다. 분류를 점수 산정에서 분리하면 독립적인 진화가 가능하다.
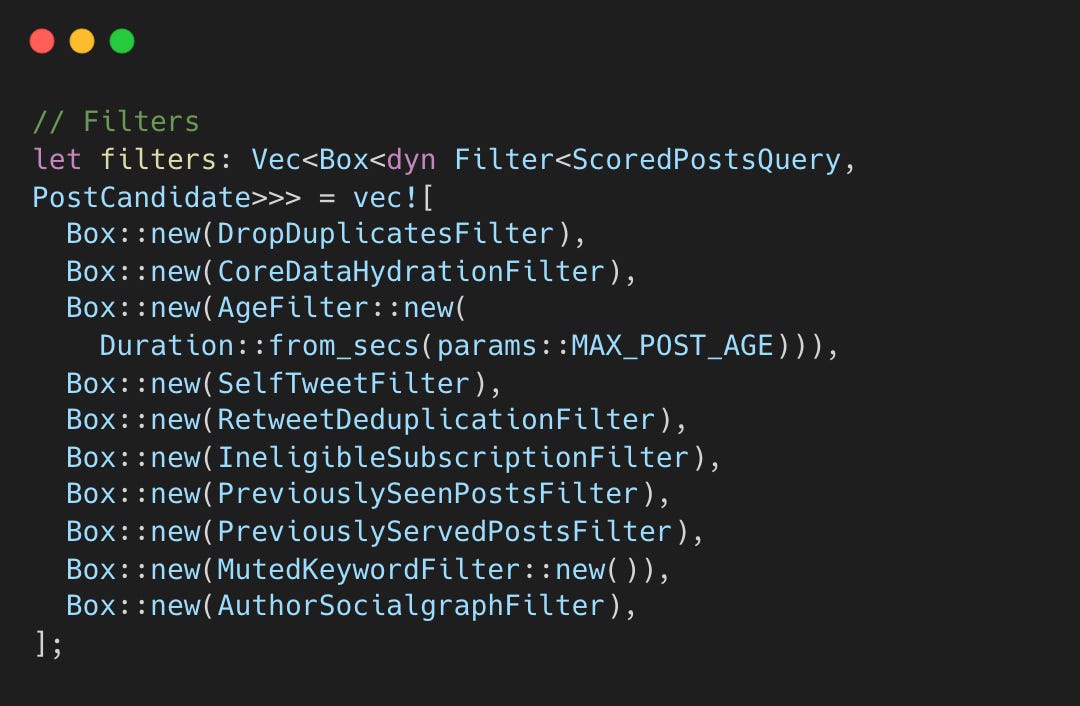
Stage 3: 사전 필터링 (Pre-filtering)
순차 필터 10개가 품질을 보장하고 불필요한 연산을 줄인다.
DropDuplicatesFilter: 소스 간 중복 제거.
CoreDataHydrationFilter: 데이터 불완전 후보 제거.
AgeFilter:
MAX_POST_AGE보다 오래된 게시물 제외.SelfTweetFilter: 본인 게시물 제외.
RetweetDeduplicationFilter: 원본과 리트윗 중복 정리.
IneligibleSubscriptionFilter: 구독 권한 없는 콘텐츠 숨김.
PreviouslySeenPostsFilter: 이미 본 게시물 제외 (블룸 필터).
PreviouslyServedPostsFilter: 현재 세션 내 중복 노출 방지.
MutedKeywordFilter: 키워드 뮤트 적용.
AuthorSocialgraphFilter: 차단/뮤트 계정 제외.
phoenix_candidate_pipeline.rs#L108-L120
Stage 4: 점수 산정 (Scoring)
살아남은 후보들은 4단계 점수 산정을 거치며 순위가 결정된다. 각 Scorer는 순차적으로 실행되며 이전 결과에 의존한다.
phoenix_candidate_pipeline.rs#L122-L132
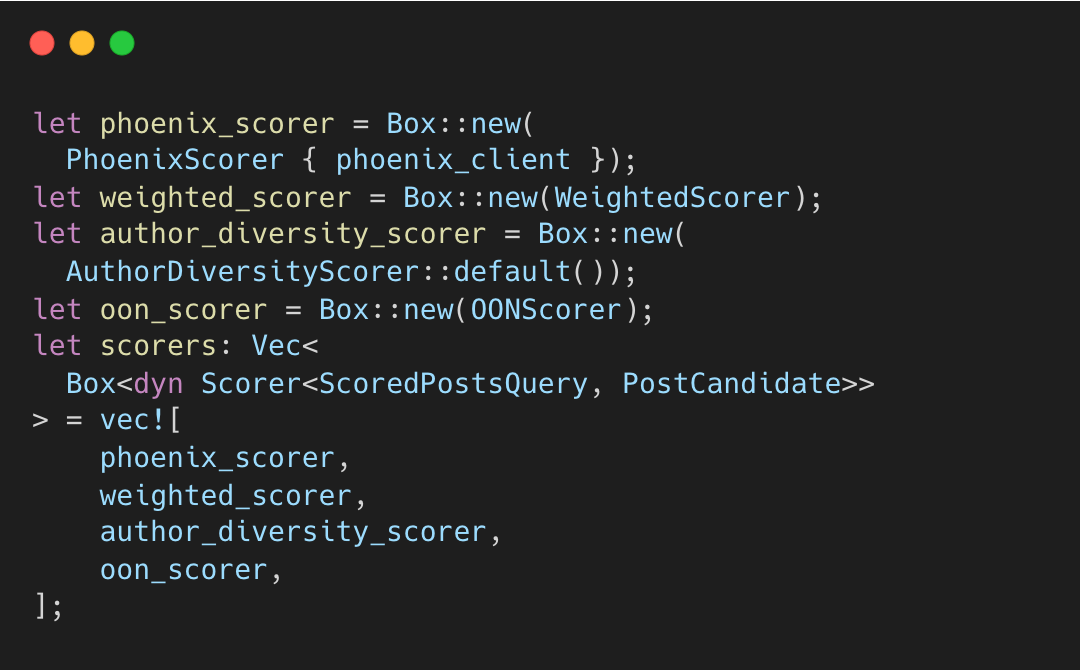
순서가 중요하다. 각 scorer가 이전 출력에 의존하기 때문이다.
Step 4.1: Phoenix 트랜스포머 예측
Phoenix는 각 게시물에 대해 인게이지먼트 확률 18개와 연속 메트릭 1개를 예측한다.
긍정적 신호:
favorite_score: 좋아요를 누를 확률reply_score: 답글을 달 확률retweet_score: 리포스트할 확률photo_expand_score: 사진을 확대할 확률click_score: 클릭할 확률profile_click_score: 작성자 프로필을 방문할 확률vqv_score: 비디오 품질 뷰(완전 시청)share_score,share_via_dm_score,share_via_copy_link_score: 공유 확률들dwell_score: 스크롤을 멈출 확률quote_score: 인용 트윗할 확률quoted_click_score: 인용된 트윗을 클릭할 확률follow_author_score: 본 후 팔로우할 확률
부정적 신호:
not_interested_score: “관심 없음”을 클릭할 확률block_author_score: 차단할 확률mute_author_score: 뮤트할 확률report_score: 신고할 확률
연속적 메트릭:
dwell_time: 게시물을 보는데 보낼 것으로 예측되는 시간
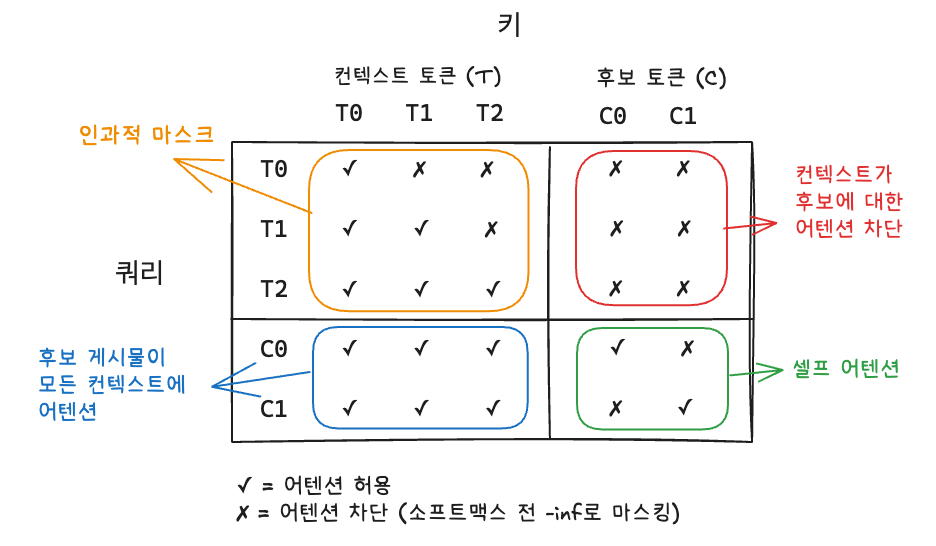
Phoenix는 커스텀 어텐션 마스크를 사용해 모든 후보를 단일 forward pass로 점수를 산정한다. 하지만 후보들의 점수가 서로에게 영향을 주지 않고 어떻게 배치할까?
독립적 점수 산정 (Batch Independence)
Phoenix는 make_recsys_attn_mask를 사용해 후보 간 상호작용을 차단한다. 즉, 배치의 다른 후보들이 점수에 영향을 주지 않으며, 오직 사용자 컨텍스트와 해당 후보만으로 점수가 계산된다.

각 후보는 사용자 컨텍스트와 자신에게 어텐션하지만, 다른 후보와의 상호작용은 차단된다.
Step 4.2: 가중치 점수 합산
WeightedScorer는 예측된 확률들에 가중치를 적용해 최종 점수 하나로 합산한다.
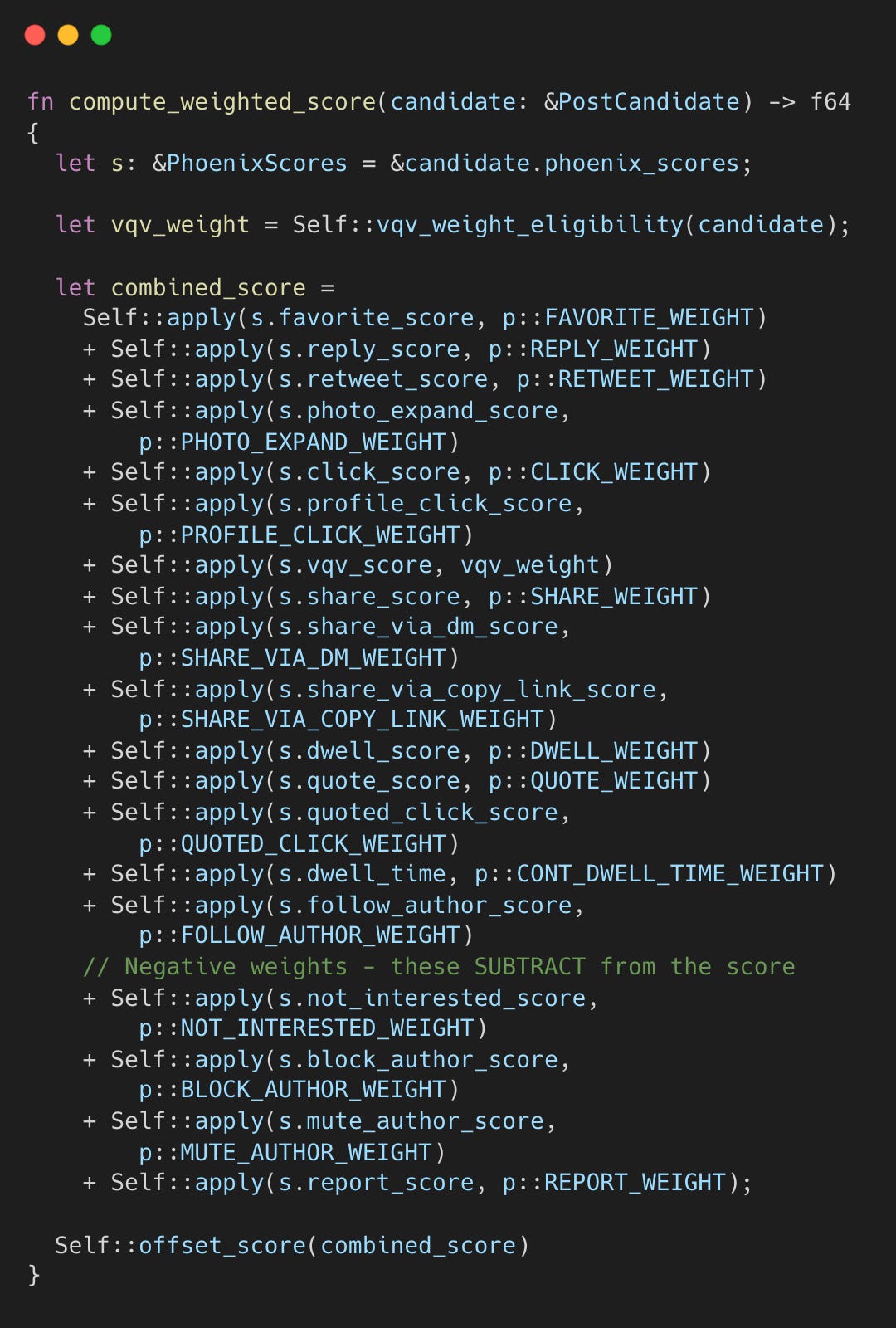
차단, 뮤트, 신고 등 부정적 신호는 점수를 깎는다.
Step 4.3: 작성자 다양성 (Decay Function)
특정 작성자의 도배를 막기 위해 지수 감쇠(Exponential Decay)를 적용한다.
author_diversity_scorer.rs#L10-L68
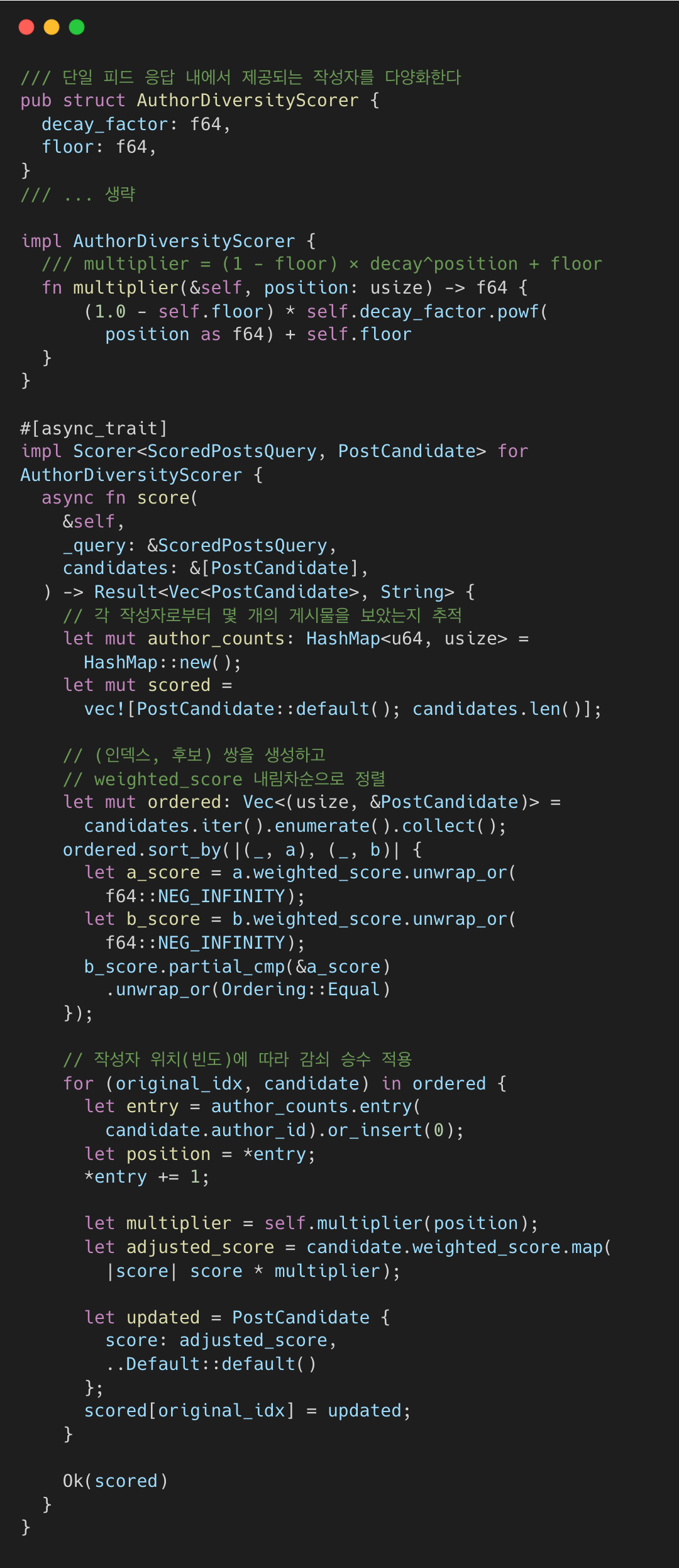
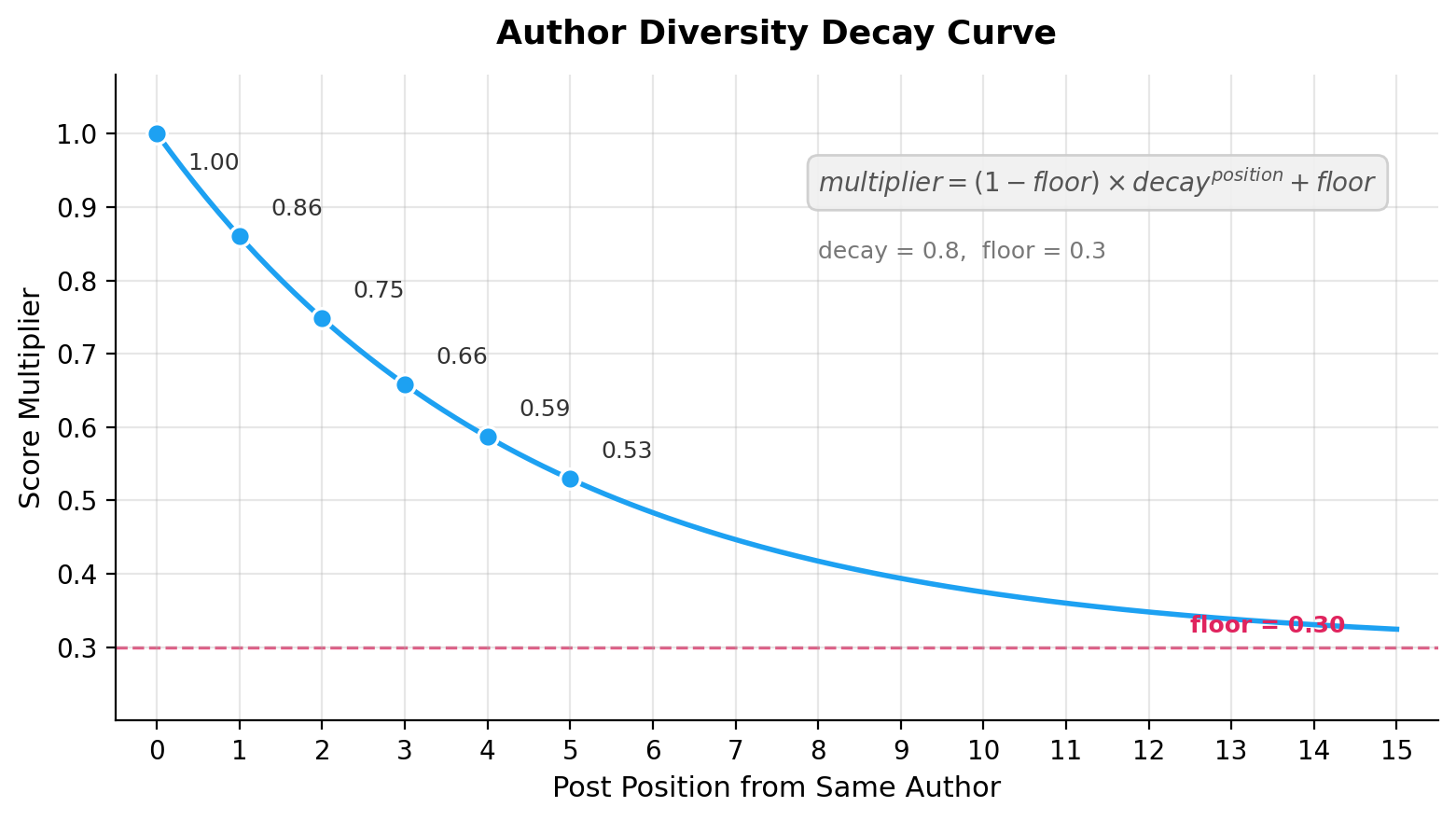
같은 작성자의 후속 게시물은 점수가 기하급수적으로 깎이지만, floor(예: 0.3) 설정으로 최소한의 노출 기회는 보장받는다.
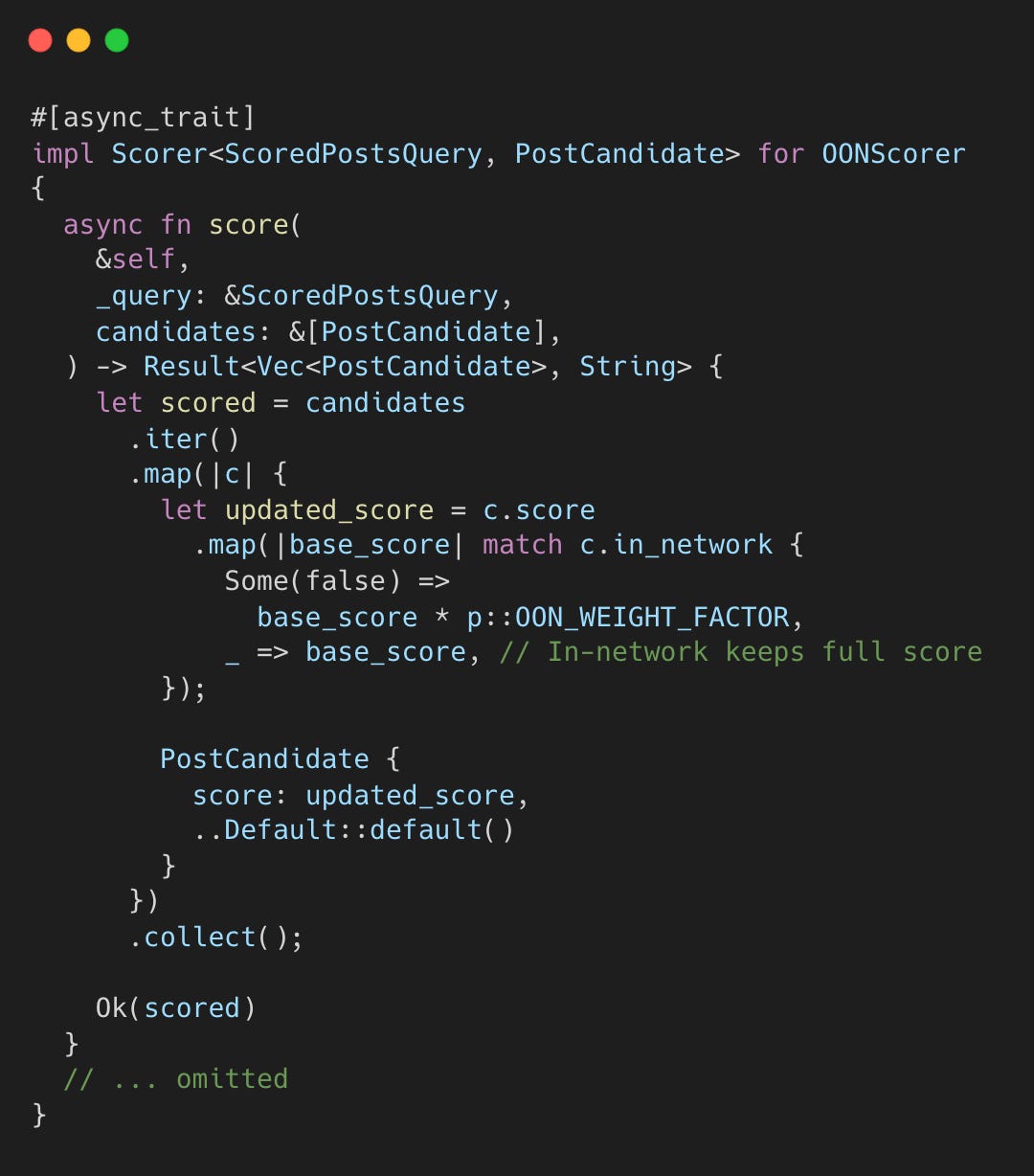
Step 4.4: Out-of-Network 페널티
OONScorer는 팔로우하지 않은 계정의 게시물 점수를 강제로 낮춘다.
Stage 5: 최종 선택 및 필터링 (Selection)
TopKScoreSelector가 점수 상위 K개를 선택한다.
top_k_score_selector.rs#L6-L15
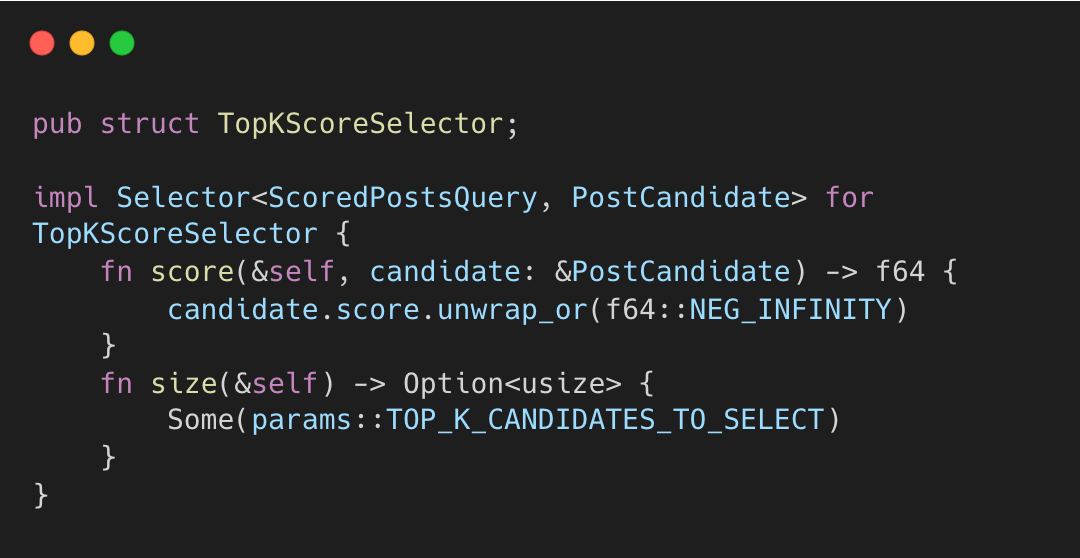
결과는 정렬되고 size()로 잘린다. 반환하기 전에, post-selection hydration과 필터링이 상위 세트를 정리한다.
가시성 필터링 (Visibility Filtering)
VFCandidateHydrator와 VFFilter는 외부 안전 서비스를 호출해 스팸, 정책 위반 게시물을 최종 제거한다.
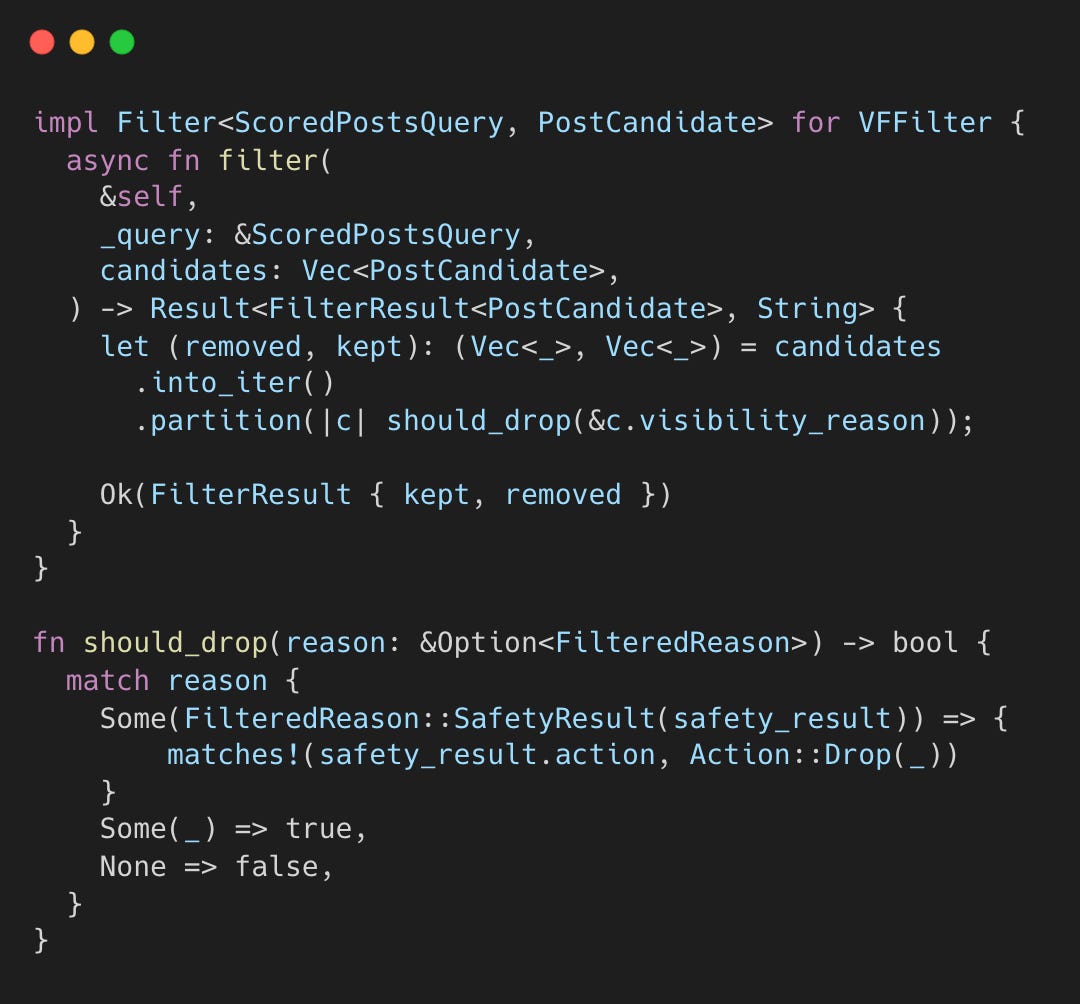
FilteredReason이 있거나 Action::Drop의 경우 후보에서 제외되고, 가시성 문제가 없는 게시물만 남긴다. 스팸이나 정책 위반 같은 특정 안전 레이블은 외부 xai_visibility_filtering 서비스가 결정한다.
대화 중복 제거
DedupConversationFilter는 동일한 대화 스레드에서 가장 점수가 높은 하나만 남긴다.
dedup_conversation_filter.rs#L8-L51
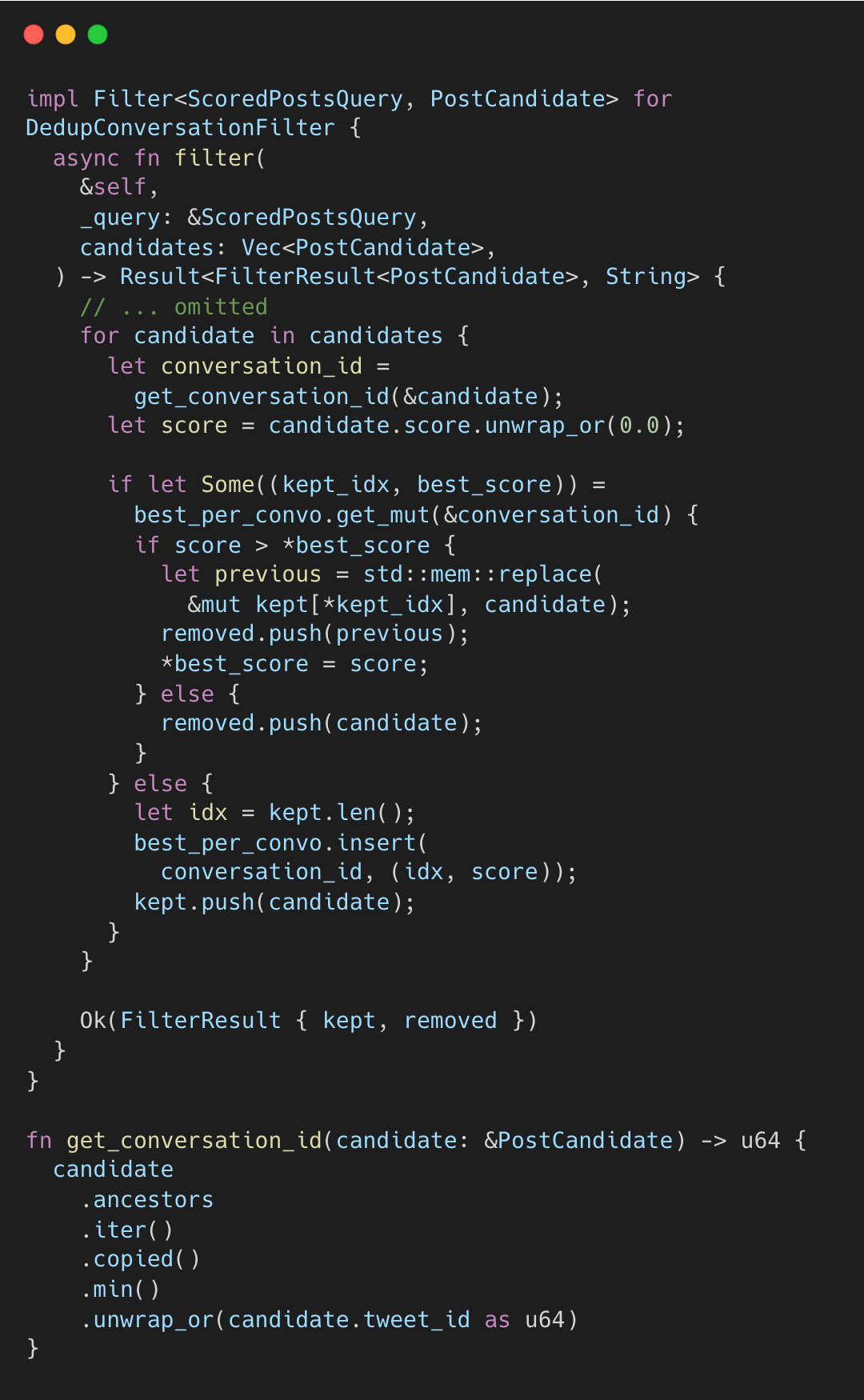
대화 ID는 최소 조상 ID, 즉 스레드의 루트다. 같은 스레드의 여러 게시물이 상위 세트에 도달하면, 가장 높은 점수만 살아남는다. 독립 게시물(조상 없음)은 자신의 tweet_id를 사용하므로 항상 통과한다.
전체 데이터 흐름
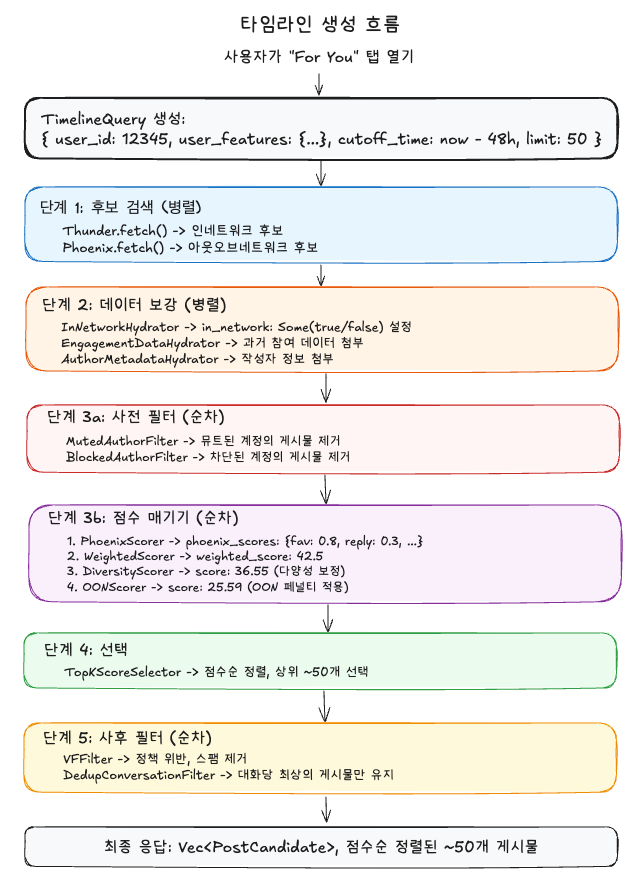
콘텐츠 제작자들이 알아야 하는 점
알고리즘 코드는 명확한 성공 방정식을 보여준다.
긍정 신호 극대화: 좋아요, 답글, 공유, 비디오 시청은 점수를 높인다.
부정 신호 회피: 차단, 뮤트, 신고는 치명적이다.
품질 > 수량: 도배는 감쇠 함수에 의해 페널티를 받는다.
왜 논란이 있는 콘텐츠는 바이럴되는가?
압도적 볼륨: 좋아요 10,000개가 차단 100개의 페널티를 압도한다. 분노 미끼(Rage-bait)는 소수의 불쾌감을 무시할 만큼 다수의 반응을 이끌어내면 성공한다.
타겟팅: Phoenix는 사용자별 예측을 수행한다. 논란성 콘텐츠는 그것에 반응하는(차단하지 않는) 사용자들에게만 선별적으로 전달된다.
인용(quote)도 반응이다: 비판을 위한 인용 트윗도 알고리즘은
quote_score(긍정 신호)로 해석한다.타이밍: 초기 반응이 폭발하면 알고리즘이 배포를 시작한다. 차단과 신고가 쌓일 즈음엔 이미 수백만 명에게 도달한 후다.
‘골든 타임’은 존재하는가?
“초기 1시간 내 좋아요 필수” 같이 정해진 규칙은 없다. Thunder는 시간 역순으로 정렬하므로 최신 글이 유리하지만 Phoenix는 의미 기반 검색이므로, 내용만 좋다면 오래된 글도 AgeFilter가 지나기 전까지는 부활할 수 있다.
하지만 초기 반응은 복리 효과를 낳는다. 초기에 긍정 신호를 받으면 확률 예측값이 올라가고, 더 많은 노출로 이어져 다시 신호를 받는 선순환(Feedback Loop)이 발생한다.